


大数据算法对体检异常代谢指标的智能甄别与疾病判断及动态模型的建立
# 研究路径
利用一家医院的三年体检大数据常用代谢指标,针对不同性别年龄分段,在不同区段内设定一定范围(如80%)人群定义为正常范围,对某个人的所有代谢指标能一次性智能甄别出超出设定范围(80%)的指标是哪些,处于的分位数给出具体值,这个大数据方法的“正常值范围”的判定和传统指南标准再结合分析,指导临床和体检患者的诊断及健康评定意识,此外,再把一些偏离大的指标在疾病集中找出具有相似特征的人群,对其所得的疾病形成词云,以此作为健康预测和疾病诊断的参考辅助。
# 应用方向
01 对各指标的健康状态做动态评测,让测试者可有横向范围比较的选择。
02 对人民大健康指标做长期的动态观察,发现一些随着物质生活环境改变而引起的人代谢寿命类的变化。
03 通过多维度指标的综合计算,从机器学习中得到新的疾病预测模型。
04 修正优化体检套餐,使之更有利于多种常见疾病的预测判断。
05 可以对单项或联合几项指标找出同样特征的人群,到其他病科甚至其他医院的数据集中找到确诊的是哪些疾病,这有助于拓展了解指标的更多意义,如发现集中在某种或几种疾病上,则可以针对此种疾病再横向拓展观测维度,单独对此种疾病特征进行学习,可能提炼出精准的计算模型。
06 也可用于单一种疾病多项指标的协同变化规律的研究。
# 应用总结
体检数据中蕴涵着大量信息特征,且对于综合性医院的体检数据往往健康人群和各种疾病人群的分布都比较均衡,数据量足够大的情况下都是趋于正态分布的,这是非常重要的可利用的一点,我们曾利用它来计算出了精准的室间偏差,跟实验做出的偏差非常接近(可能后续发表,有兴趣的朋友可以联系或关注下),对于临床需求,我们是更希望能从众多的项目维度中学习出某种疾病或健康的模型,发觉出人脑不可能观测出的特征(当然这里我们必须忽略它的可解释性,因为本身多维度空间的东西就是无法想象的,不能接受这点的话,科学就要永远停留在人类有限的认知上)。
可能是大数据时代还处于萌芽期、也可能是数据资源的获取困难或跨界学科的分析技术欠佳,目前在医学大数据的学术领域并没有太多的有重大发现的文章,(且不谈商业领域的“黑匣子”),大多还是传统的,从经验研究通路,由理论设计实验,从实验得出数据,最后才拿数据统计来印证实验,而这样的过程,一开端还是由人的思维认知为起始的,数据分析并没有能真正发挥它超越人认知的框架。
所以,要突破这种习惯思维模式,从数据本身入手,又在实际经验的指引下,逆向分析研究,至少才有可能突破经验的禁锢拓展发现未知领域!
# 后续跟进
本文重在打开一种思路方法,希望帮助于今后学者向以上6个方向上的深入研究,后期也会把python的源代码发布在GitHub上大家共同学习讨论。
我们用到了很多的数据处理手段,且依赖动态的训练集数据,适合做长期观测发现,因此如需开展,需要建立数据分析平台软件,内嵌算法处理,并不适合用常规的统计软件分析,如有兴趣开展的医院可联系我单位提供免费的平台分析系统并做个性化定制。
# 数据集介绍
体检集:来源于天津市第三中心医院
疾病集:来源于天津市北辰医院
数据前处理
01 清洗数据:去除非法字符和含空值记录;
02 选取与观测指标:需根据数据表的具体形式,筛选出此数据集中尽量多的记录又含有最多的项目组合(本文用了算法筛选,如事先知道最多的组合项目也可直接取维度指标),原始数据形式如下。
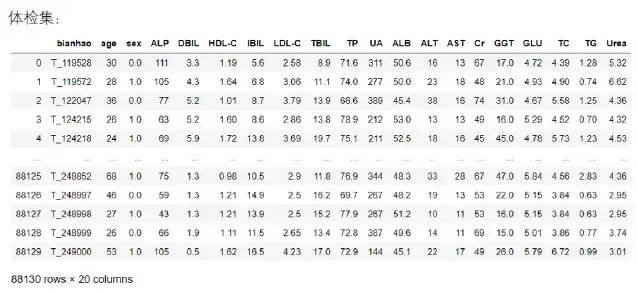
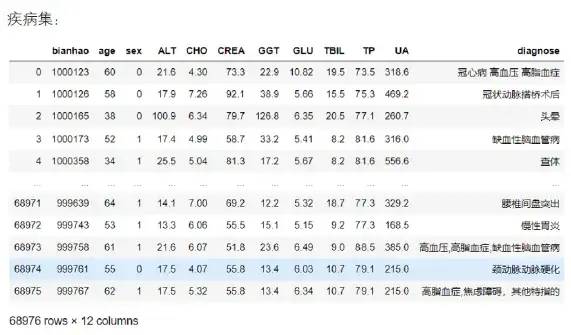
以上体检集含8万多条数据,17个检测项目维度指标;疾病集6万多条数据,8个检测项目指标。
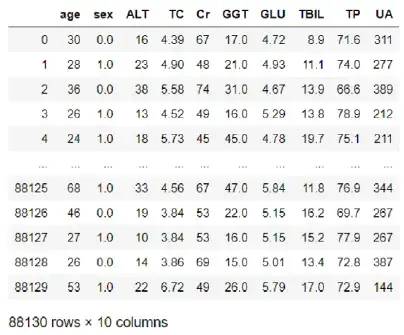
03 统一维度:此文的疾病集维度指标较少,要和体检集统一维度指标,只能在体检集中取出疾病集中有的项目,其他舍弃,重新整理后得到的体检集如下表:
随机抽取一人,自定义比较区间
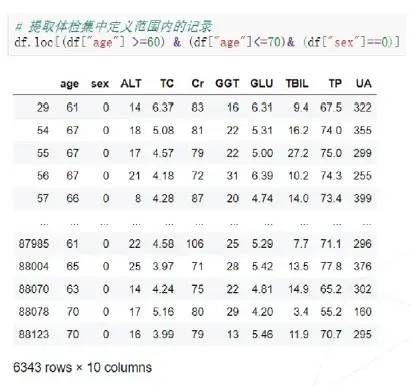
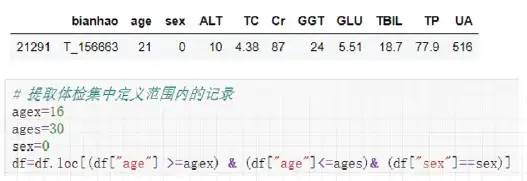
01 在体检集中随机抽取一人:

02 针对其年龄,定义比较范围:如抽取人63岁男,我们定义比较范围为60-70岁的男性范围。
03 提取体检集中定义范围内的记录,作为体检比较集:
04 计算所需参数:
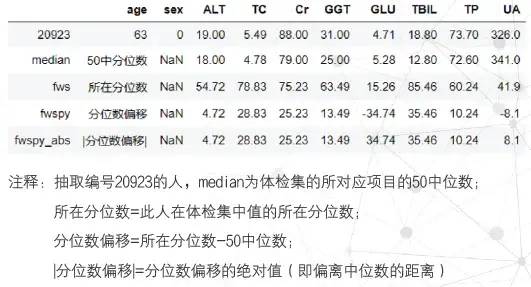
选择项目组合到疾病集中比较
选取分位数偏移最大的几个指标,到疾病集(也做相应范围的参比集)中去查询具有此相似度的人群都患有怎样的疾病,这里我们选择偏离最大的前五个维度:TBIL、GLU、TC、Cr、GGT。
01 在疾病集中筛选出相应范围的记录作为疾病参比集:
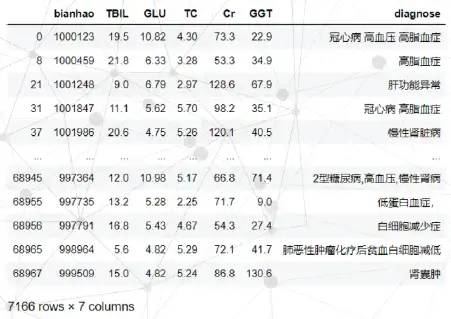
02 计算空间欧式距离,并按距离排序:计算疾病参比集中的每条记录到抽取人的欧式距离,并按距离排序,剔除掉距离远的5%数据后如下表。
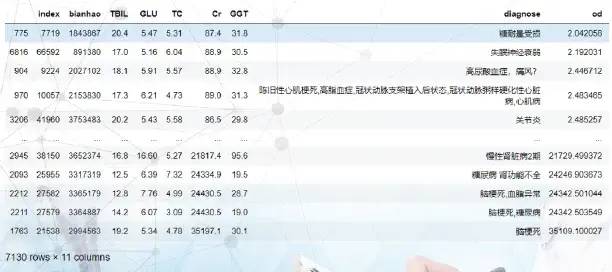
03 选取一定距离半径范围内的人群作疾病参考:
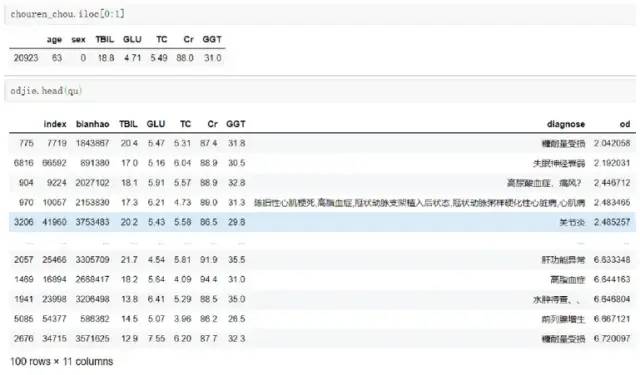
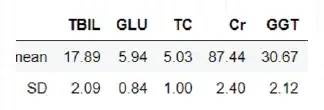
• 注释:以上第一个表为被选取人的偏离最大的几个指标值,第二个表为疾病集中取出的前100个同样指标人数值;按距离从小到大排序。这里可以从每个项目的数值上观测决定取前多少距离的人群形成簇;以下选前100人形成的簇。
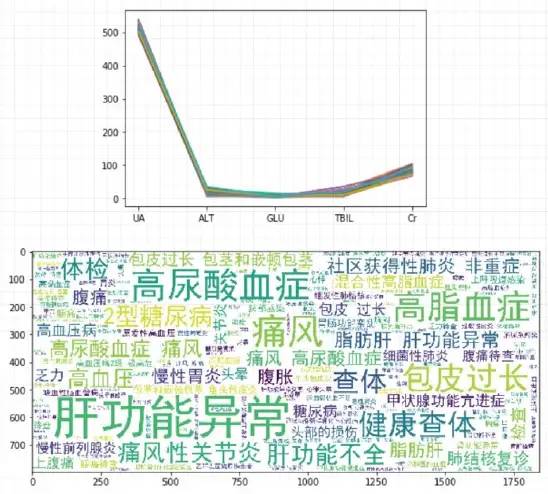
04 绘制簇图:选取前100个相近距离的人,和被选取人的对应指标值做比较,并形成簇图如下。
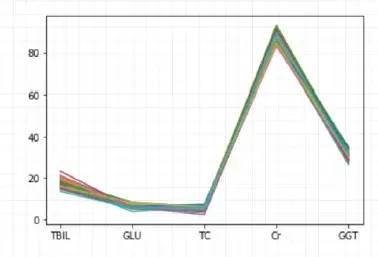
• 注释:上图标横轴为筛选的项目(按偏离程度从大到小排列),纵轴是指标数值。此图只直观看下聚类的集中程度,选取的人数越多,簇带越集中越细聚类越好,同时可计算出每个项目的簇内SD值来参照,如下:
词云展示疾病风险
将疾病参考集中的所有人患病词汇形成词云展示,即具有与所选人是同样特定指标相近的人群的人所得的疾病(也可以只用簇内人群的,或根据具体情况自定义半径范围)。

另抽取一人的图形数据
以上抽取的是63岁的老人,周围都是老年疾病多,下面再抽取1个年轻人,可以自行尝试下其他的抽取。
小结
此方法需关注的主要是三点:
01 超过预设范围的指标有哪些,超出度是否可接受(利用跟中位数的比较,形成簇的观察,再最后词云的展示临床经验等);
02 选定哪些指标进入疾病集中去筛选比对,选的少了不能锁定综合指标确定的疾病,选的多了容易过拟合没有聚类,还有就是不论多少这些指标都不是其疾病的反应性指标,也就是说检测的指标跟所得的疾病无关,这都是要考虑的问题;
03 在疾病集中筛选出的簇,要同时和仅年龄、性别筛选集对比来看,因为当选定指标没有特定反应意义时,所提出的簇和词云就更多的是受年龄性别影响的了。
最后要着重的是,重在工具和方法,有了方便计算观测的软件,再连上有资源的数据库,才有可能在日常工作中发现更多。
编辑:骆秉涵


