


ChatGPT在临床微生物学实验室不同病例场景中的性能评价
【摘要】目的 基于人工智能(AI)的工具可以重塑医疗实践。其中,ChatGPT被认为是最流行的基于AI的对话模型之一。然而,不同版本的ChatGPT在不同环境下的性能还需要进一步评估,以评估其在各种医疗相关任务中的可靠性和可信度。因此,本研究旨在评估免费ChatGPT-3.5和付费版ChatGPT-4在10个不同的诊断临床微生物学病例场景中的性能。方法 目前的研究采用了METRICS清单(模型、评估、时间/透明度、范围/随机化、个体因素、计数、提示/语言的特异性),用于标准化基于AI的医疗研究的设计和报告。在2023年12月3日测试的模型包括ChatGPT-3.5和ChatGPT-4,对ChatGPT生成的内容的评估是基于CLEAR工具(完整性、无虚假信息、证据支持、适当性和相关性),采用5点李克特量表(Likert scale)进行评估,CLEAR评分范围为1-5分。ChatGPT输出由两名评分者独立评估,评分者之间的一致性基于Cohen’ s κ统计量。3位不同专业水平的微生物学家在对约旦常见病例进行内部讨论后,用英语创建了10个诊断临床微生物实验室的病例情景。主题范围包括细菌学、真菌学、寄生虫学和病毒学。根据CLEAR工具定制特定的提示,并在提示每个案例场景后选择一个新的会话。结果 ChatGPT-3.5的5个CLEAR项目的Cohen’ s κ值为0.351-0.737,ChatGPT-4 的Cohen’ s κ值为0.294-0.701,这表明两者的一致性一般到良好,适合进行分析。根据CLEAR平均得分,ChatGPT-4优于ChatGPT-3.5(平均值:2.64±1.06 vs. 3.21±1.05,P= .012,t检验)。根据CLEAR项目的不同,每个模型的性能也不同,其中“相关性”项目的性能最低(ChatGPT-3.5为2.15±0.71,ChatGPT-4为2.65±1.16)。只有ChatGPT-4在“完整性”“无虚假信息”和“证据支持”方面的表现最好(P= .043)。在抗微生物药物药敏试验(AST)查询中,两种模型的性能水平都最低,而在细菌和真菌鉴定中性能水平最高。结论 对ChatGPT在不同诊断临床微生物学案例场景中的表现进行的评估显示,ChatGPT-4的表现优于ChatGPT-3.5,ChatGPT的性能因评估的具体主题不同而存在明显差异。两种ChatGPT模型的主要缺点是倾向于生成缺乏所需重点的不相关内容。尽管ChatGPT在这些诊断微生物学案例场景中的整体性能充其量可能被描述为“高于平均水平”,但考虑到在少数情况下发现的局限性和不令人满意的结果,仍然存在很大的改进潜力。
【关键词】人工智能聊天机器人GPT-4;人工智能应用;医学和诊断微生物学
人工智能(AI)在医疗保健领域的应用标志着医疗诊断方法进入变革时代。这涉及更高效的实验室流程以及改进的工作流程、患者护理和满意度。2022年11月30日公开推出的ChatGPT就是可以产生这种变革的基于AI的对话模型之一。然而,基于AI的模型在医疗保健中的成功应用需要更广泛和稳健的研究来评估这些模型的性能、可靠性和可能的缺点。尽管基于AI的模型(如ChatGPT)在医疗保健领域具有巨大的潜力和前景,但需要研究的挑战之一是不同测试对象的性能差异。不同医疗领域的性能差异可能与多个因素有关。例如,训练数据的质量是基于AI模型性能的重要决定因素,在罕见医疗条件下性能低于标准;另一个因素是各种模型的架构,其中图像分析和文本数据处理可能各不相同。此外,各医疗领域的监管和标准化指南的变化速度可能超出基于AI的模型的知识极限,上述标准和指南可能不易用于训练模型,从而影响这些模型性能[例如,CLSI的抗微生物药物敏感性测试(AST)标准]。
在医疗实践中,某些专业尤其被认为最适合从AI集成中获益,从而激发人们对潜在工作流程改进的热情。尽管如此,人们对AI自动化可能导致失业的担忧也值得注意。基于AI的模型具有高效处理和分析大量数据集的能力,因此,放射科和病理科(包括临床病理科)对精确度和快速周转时间要求极高,可被视为从AI转型中获益的主要专业。这种能力对临床微生物学的实践具有重大影响,AI集成可以改变传染病的诊断和治疗方法,最终改善对患者的护理。最近构思了一份清单,用于规范基于AI的医疗保健研究的设计和报告,该清单被称为“METRICS”(模型、评估、时间/透明度、范围/随机化、个体因素、计数、提示/语言的特异性)。该框架考虑了测试模型的特征、评估方法以及用于创建模型查询的数据集的特征。此外,新设计的工具“CLEAR”(完整性、无虚假信息、证据支持、适当性和相关性)专门用于规范模型生成内容的评估方法。
基于以上几点,本研究的目的是评估ChatGPT在不同诊断临床微生物实验室病例场景下的性能。通过深入了解ChatGPT在临床微生物学领域的优势和局限性,本研究可以获得更多关于基于AI的模型在医疗保健领域作用的知识基础。
一、材料与方法
1. 研究设计:目前的研究设计遵循标准化的设计和报告方法,用于评估ChatGPT在诊断临床微生物学实验室病例场景中的性能,研究设计基于METRICS检查表的全部细节将在下文进行了说明,对ChatGPT生成内容的评估基于CLEAR工具。由于没有人类或动物参与者或实验,因此免于伦理许可。进行这项研究的框架是基于在医疗保健领域保持ChatGPT评估的严谨性和标准化的尝试。利用了最近设计的名为“指标”的METRICS清单,清单提供了一个详细的框架,用于标准化研究的设计和报告,评估基于AI的模型在医疗保健领域的表现,仔细考虑了以下因素:(1)使用的确切AI模型及其设置;(2)评估方法;(3)测试AI模型的确切时间和查询来源的透明度;(4)测试的健康主题范围和随机选择查询的过程;(5)查询选择和AI模型输出主观评价中的个体因素;(6)反映样本量的查询数以及(7)用于生成输出的提示的特异性和使用的确切语言。此外,本研究采用了CLEAR工具,为 AI模型产生的输出的主观评价提供了坚实的基础,具体考虑以下几点:(1)生成内容的完整性;(2)生成的内容无虚假信息;(3)支持生成内容的证据;(4)所生成内容的适当性,即通俗易懂、简洁明了、条理清晰;(5)内容的相关性,即没有不相关的内容。
2. 使用的AI模型、模型测试的时间、查询计数和提示/语言的特异性:本研究使用了ChatGPT的两个版本:GPT-3.5版本(可免费公开获取)和高级 GPT-4 版本(可通过付费服务获取)。对这两个模型的测试是在各自的默认配置下进行的,以确保生成内容的可重复性。这项研究涉及在每个ChatGPT模型上执行10次不同的查询,选择这个数量是为了对每个查询进行实用而全面的分析。选择这种方法是为了在生成和评估AI生成的回复时更有针对性,而无需根据ChatGPT的速率限制延长查询时间。对于每次查询,ChatGPT的提示都是一致的和具体的开场白:“作为一个有经验的微生物学家,对以下查询提供一个完整、准确、循证、适当和相关的答案”。这种标准化方法在两个模型的所有查询中都保持不变。为防止任何潜在的学习或反馈环影响模型的算法,每次新查询前都选择“新聊天”,不使用“重新生成答复”选项。提示方法基于Meskó的教程,所有查询均用英语进行,每个查询的措辞均在公共数据存储库“面向临床微生物实验室的场景中的ChatGPT性能”(https://doi.org/10.17605/OSF.IO/92UVZ)中列出。
3. 个人参与查询生成和ChatGPT输出评估:这些查询源自三位作者共同努力创建的案例场景:一位顾问、一位专家和一位高级住院医师,全部从事临床病理学/微生物学和免疫学研究。这些病例基于约旦临床微生物学实验室的典型案例,涉及一系列子专业,包括细菌学、寄生虫学、真菌学和病毒学。内容大致分为三个主题:第一,微生物鉴定技术(生化、分子、显微);第二,AST,特别关注细菌对抗微生物药物的内在耐药性问题和AST的金标准方法;第三,临床微生物学诊断方法,特别关注需要注意的质量控制(QC)问题、关键结果报告和实验室安全协议。查询的最终形式包含了主观因素,因为这些查询是根据三位作者的内部讨论最终确定的,三位在微生物学和免疫学方面的专业知识水平各不相同。对生成的ChatGPT内容的评估由第一作者和第二作者独立进行(分别为评分者1和评分者2),两位都获得了JMC颁发的临床病理学/微生物学和免疫学证书,采用Cohen’ s κ统计量评价两者间的一致性。评估基于CLEAR工具,根据5点李克特量表(Likert scale)评估了每项回复的5个属性(完整性、无虚假信息、证据支持、适当性和相关性),每项属性的评分范围为5分(优秀)-1分(差)。评估之前,三位作者进行了联合讨论,根据CLEAR工具指南确定最佳答案的标准。
4. 微生物学测试主题的范围和随机化:本研究的主题是诊断临床微生物实验室,具体选取10个主题如下:(1)在卵和寄生虫(O&P)检查中分离非病原体寄生虫的意义,可能提示粪便污染;(2)采用通过肉汤微量稀释测定最低抑菌浓度(MIC)作为评估粘菌素敏感性的标准方法;(3)耐甲氧西林金黄色葡萄球菌(MRSA)对所有β-内酰胺类抗生素的耐药性;(4)肠球菌对克林霉素的固有耐药性;(5)利用简单的直接技术(菌落形态学和芽管试验)鉴别白色念珠菌;(6)解读尿培养结果以诊断尿路感染(UTI);(7)通过生化和血清分型检测鉴定血液样本中的布鲁氏菌属感染,并特别考虑安全性问题;(8)病毒性呼吸道病原体多重实时聚合酶链式反应(PCR)检测中循环阈值(Ct)的解读,以及相关的质量控制问题;(9)痰培养前评估样本质量的意义以及(10)基于Kaufmann-White分型的肠道沙门菌鉴定及血清分型。两种ChatGPT模型测试主题的选择是非随机的,特意侧重于临床微生物实验室(尤其是约旦的)经常遇到的情况。
5. 统计和数据分析:本研究的统计分析采用IBM SPSS Statistics for Windows 26,统计显著性水平设定为P<.05。在使用Shapiro-Wilk检验确认数据分布正态性的基础上,采用配对t检验来检验配对观测值的平均差异。为了评估每个ChatGPT模型中CLEAR工具不同项目之间的差异,采用了相关样本Friedman双向等级方差分析。在比较两个ChatGPT模型生成的内容时,为了评估评分者之间的可靠性,使用了Cohen’ s κ统计量来衡量两个独立评分者之间的一致程度。对Cohen’ s κ值的解释分类如下:小于0.20表示一致性差,0.21-0.40表示一致性一般,0.41-0.60表示一致性中等,0.61-0.80表示一致性好,0.81-1.00表示一致性极佳。最终CLEAR分数为两名评分者评分的平均值,为了对CLEAR分数进行描述性解释,以表明生成内容的质量(五个项目的分数总和除以5),分数被划分为以下类别:1-1.79分为“差”;1.80-2.59为“满意”;2.60-3.39为“好”;3.40-4.19为“很好”;4.20-5.00为“优秀”。
二、研究结果
1. ChatGPT-4在10次查询中的表现优于ChatGPT-3.5:通过比较两个ChatGPT模型的每个CLEAR项目,我们观察到两个评分者之间的一致性和统计学显著性的一致性。对于ChatGPT-3.5和ChatGPT-4,Cohen’ s κ值表明统计学显著,评分者间的一致性从一般到良好(表1)。
表1. 按每个CLEAR项目分层评估ChatGPT-3.5和ChatGPT-4输出时的评分者之间的一致性

注:C:完整性;L:缺乏虚假信息;E:证据支持;A:适当性,R:相关性;SD:标准差
根据CLEAR平均得分对两种ChatGPT模型进行了50次两两比较,其中ChatGPT-4在31次比较中得分高于ChatGPT-3.5(62.0%),在18次比较中得分相同(36.0%),而ChatGPT-3.5仅在一次比较中得分高于ChatGPT-4(2.0%,见表2)。
表2. 在CLEAR项目中测试的两个ChatGPT模型之间的两两比较
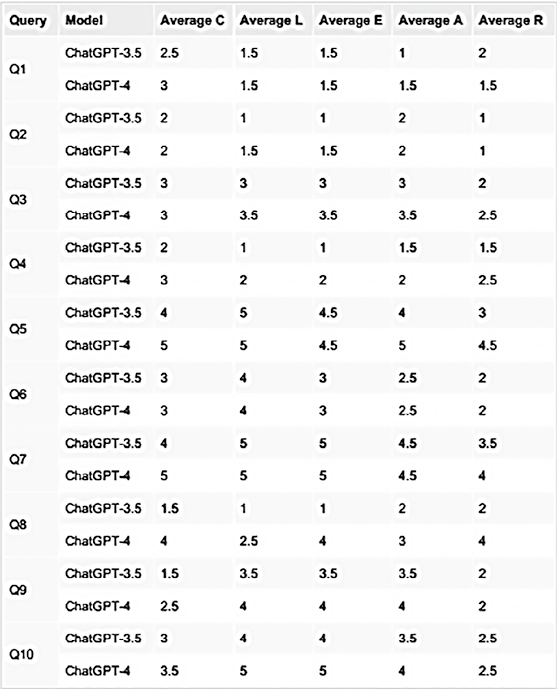
注:平均分的计算方法是两位评分者的评分之和除以2,比较的依据是两位评分者对每个查询(Q)的每个CLEAR项目的平均评分
2. 每个CLEAR项目的ChatGPT-3.5和ChatGPT-4性能:根据10次查询的平均值之和得出的CLEAR总分被用来比较每个ChatGPT模型在五个CLEAR项目中的表现。ChatGPT-4在“适当性”“无虚假信息”和“完整性”项目上的表现优于ChatGPT-3.5,差异具有统计学意义(见图1)。
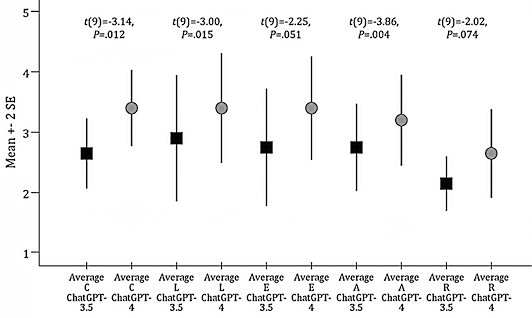
图1. 每个CLEAR项目的ChatGPT-3.5与ChatGPT-4的平均性能比较
3. 每个CLEAR项目的性能在模型内存在差异:通过比较各ChatGPT模型的性能,观察基于CLEAR项目的差异。在ChatGPT-3.5中,尽管表现存在差异,但“无虚假信息”得分最高,“相关性”得分最低,差异无统计学意义(χ24 = 4.907,P = .297)。ChatGPT-4在完整性、无虚假信息和证据支持方面表现最好,在相关性方面表现最差(χ24 = 9.863,P = .043)。
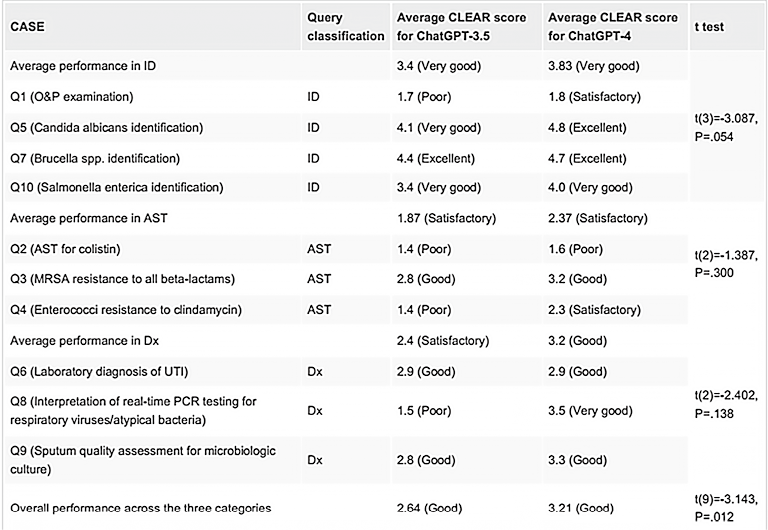
4. ChatGPT-3.5与ChatGPT-4的查询性能比较:管ChatGPT-4和ChatGPT-3.5在总体性能上都显示出“良好”的性能,但 ChatGPT-4的性能优于ChatGPT-3.5,两者之间的差异具有统计学意义(平均值:2.64±1.06 vs. 3.21±1.05,P =.012)。对于每个主题,在涉及AST评估的查询中观察到的性能最低,两个模型的性能仅达到令人满意的水平,而在微生物鉴定类别中性能最高,性能非常好(表3)。
表3. 评估每个主题的ChatGPT模型性能和跨主题的整体性能
三、讨论
诊断临床微生物的实践要求一丝不苟,因此,在这样一门高度精确的医疗学科中,持续评估AI模型的性能非常重要。在不久的将来,AI生成的健康信息的可靠性可能会被证明对包括微生物学家在内的医疗专业人员有用,甚至是必不可少的。虽然基于AI的模型(如ChatGPT)在各种医疗保健学科中显示出良好的前景,但由于其目前的局限性,有必要对其进行持续开发和严格评估,以确保其在不同临床环境中的可靠性和准确性。
本研究采用了一种名为“CLEAR”的新工具,该工具有助于ChatGPT等基于AI的模型产生的信息进行标准化评估。通过识别这些模型产生的知识差距、信息不准确性、模糊性和偏差,CLEAR工具提供了一个系统评估健康查询回复的框架。随后,研究结果可以揭示这些基于AI的工具需要改进的地方。在目前的研究中,研究结果指出了两种ChatGPT模型的性能各不相同,具体来说,虽然对大多数查询的回复令人满意,但某些ChatGPT回复包含严重错误,凸显了如果将此类内容用于临床决策,可能会产生有害结果的风险。目前的研究评估了 ChatGPT-3.5和ChatGPT-4的性能,发现后者的高级模型的CLEAR分数更高,因此显示出更强的能力。尽管在本研究中对ChatGPT性能的评估存在主观性,但两个模型的所有CLEAR项目的评分者之间的一致性尚可,支持了所使用方法的可信度。
在这项研究中,特别是ChatGPT-4,在所有CLEAR项目中表现出了更高的性能评级,表明这一大型语言模型的演变有了显著的改进。在广泛的医疗保健相关研究中也观察到了这种模式。例如,Hirosawa等人的研究表明,与医生相比,ChatGPT-4在鉴别诊断列表中获得了正确的诊断,比ChatGPT-3.5表现更好。此外,Teebagy等人的研究表明,在眼科知识评估项目考试中,ChatGPT-4的表现优于ChatGPT-3.5;Massey等人强调,与ChatGPT-3.5相比,ChatGPT-4在回答骨科住院医生评估考试问题的能力方面表现更优;Moshirfar等人最近的一项研究表明,与ChatGPT-3.5和专业人员相比,ChatGPT-4在回答眼科StatPearls问题方面具有显著的性能优势。尽管免费访问版本(ChatGPT-3.5)的性能较差,但该模型在提供准确信息方面表现出了优势,尤其是在CLEAR量表的“无虚假信息”项目中。然而,在“相关性”项目上的表现较差,这凸显了该模型需要加强对上下文的理解。同样,ChatGPT-4在“相关性”项目中的表现也是最差的,这表明需要加强ChatGPT生成中肯的、与上下文相适应的回答的能力,包含不必要内容的倾向可能会削弱 ChatGPT在医疗实践中的实用性。另一方面,ChatGPT-4在“完整性”、“无虚假信息”和“证据支持”方面的表现值得注意,提示该先进模型能够提供全面、准确、循证的健康信息。
相反,仔细观察ChatGPT生成内容的细粒度会发现某些不足。在某些情况下,质量控制措施的必要性和报告关键结果的紧迫性等关键方面被忽视了。这些缺陷被认为是至关重要的,因为它们会严重影响患者的治疗效果。此外,两种ChatGPT模型在回答与AST相关的查询方面都显示出局限性,值得注意的是,这两个模型都错误地建议将克林霉素作为治疗肠球菌感染的一种选择,并且没有提到评估不动杆菌分离株中粘菌素敏感性的适当标准方法,这种不准确可能导致无效的治疗选择,并导致患者结局不佳。还有,ChatGPT-3.5在实时多重PCR病例解读方面的性能欠佳,这提示其在处理复杂诊断过程方面存在局限性,而复杂诊断过程是现代临床微生物学实验室实践中的关键因素。在本研究中,解决这一缺陷的方法是不断完善基于AI的模型,ChatGPT-4在同一案例中的能力明显增强就证明了这一点。最近的一项研究强调了ChatGPT-3.5在医学微生物学方面的表现低于平均水平,该研究将ChatGPT-3.5与学生的表现进行了比较。以前的研究已经清楚地概述了ChatGPT生成的内容在不同的医疗相关环境中可能存在的偏差和事实不准确性。医疗领域这一明显趋势的一个可能解释是,这些基于AI模型的训练数据,获取受版权保护的资料和每年更新的指南的途径有限,知识有限。因此,需要应对的一个挑战是需要将信息动态纳入AI算法,以确保生成最新、准确的内容。
最后,本研究还存在一些不足之处,值得认真考虑。这包括评估过程的主观性、描述性,以及评分者不同专业水平的影响。这反映在相关性和适当性项目的κ值相对较低。此外,构建案例场景虽然代表了常见的临床微生物学实验室场景,但可能缺乏减轻选择偏差所需的随机化。此外,我们承认样本量较小,仅包含10个查询,但它可以为未来更全面的研究奠定基础,解决基于AI的模型在临床微生物学中的效用,包括常见和罕见的病例场景。此外,研究中仅使用英语可能无法反映ChatGPT在其他语言或文化背景下的表现差异。
四、结论
据我们所知,目前的研究是首次尝试使用标准化方法评估ChatGPT在诊断微生物学中的性能。虽然两种ChatGPT模型在某些情况下都显示出了令人满意的结果,但考虑到这一医疗实践领域对精确性的需求,它们在临床微生物学中的应用目前仍处于起步阶段。一个主要的问题是,在这两种模型的回复中经常会出现无关内容。研究结果表明,ChatGPT等基于AI的模型正在不断进步,其中ChatGPT-4在临床微生物学中的表现优于ChatGPT-3.5。但是,仍需要通过不断改进和有针对性地训练来提高性能,尤其要重视提高相关性和上下文的准确性。此外,开发专为医疗目的设计和训练的AI模型也是获得高精度AI优势的另一种方法。
最后,考虑到研究的局限性,很难给本研究中ChatGPT的表现贴上特定的标签(如高于平均水平、良好或一般)。尽管如此,本研究的结果凸显了将基于AI的模型整合到临床微生物学实践中的潜力和挑战。从积极的方面来看,AI模型可以改善临床实验室的工作流程,促进报告布局设计,细化实验室操作流程。然而,研究结果也提出了对两种ChatGPT模型的合理担忧,特别是强调了对QC措施的不够重视,而QC措施是临床环境中的一个关键方面。![]()
编译节选自:Cureus. 2023 Dec 16; 15(12): e50629.


