


基于机器学习的差值检查法在肿瘤标志物检测中标本错误识别的有效性
【摘要】目的 肿瘤标志物检测中的标本识别性错误可能导致严重的诊断和治疗差错。本研究致力于开发一种基于机器学习(ML)的创新性差值检测方法,旨在有效识别此类错误,以克服传统检验方法的局限性。方法 实验用五种肿瘤标志物包括:甲胎蛋白(AFP)、糖类抗原19-9(CA19-9)、糖类抗原125(CA125)、癌胚抗原(CEA)和前列腺特异性抗原(PSA)。共采纳246,261条记录,其中179,929条记录用于模型训练,66,332条记录用于性能评估。基于随机森林(RF)和深度神经网络(DNN)方法开发了一个误识别错误检测模型。同时进行了1%随机样本重排的计算机模拟实验。评估了所开发模型的性能并与传统的差值检查方法进行了比较,如百分比变化(DPC)、绝对值百分比变化(absDPC)和参考变化值(RCV)。结果 DNN模型在检测样本识别错误方面优于RF、DPC、absDPC和RCV方法。对应AFP、CA19-9、CA125、CEA和PSA分别达到了0.828、0.842、0.792、0.818和0.833的平衡准确率。尽管RF方法的性能优于DPC和absDPC,但其与RCV相比表现相当或更低。结论 本研究结果表明,基于机器学习的差值检查方法在检测样本误识别错误方面比传统差值检查方法更有效。特别是DNN模型相比RF、DPC、absDPC和RCV方法表现出更优越且稳定的检测性能。
【关键词】人工智能;自动验证;深度神经网络;差值检查;机器学习;肿瘤标志物
肿瘤标志物在癌症的诊断、预后评估和治疗监测中具有重要作用。其检测结果的准确性直接影响临床决策的制定和患者的治疗效果。本文分析了五种常用的肿瘤标志物:甲胎蛋白(AFP)、糖类抗原19-9(CA19-9)、糖类抗原125(CA-125)、癌胚抗原(CEA)和前列腺特异性抗原(PSA)。AFP:用于辅助诊断肝细胞癌,并筛查高风险患者。治疗后的低AFP值与良好的预后相关。CA19-9:用于辅助诊断胰腺癌,并监测胰腺癌的治疗效果。CA-125:用于辅助诊断卵巢癌,并监测卵巢癌的治疗效果。CEA:主要用于监测转移性结直肠癌的治疗效果,因其对结直肠癌的高度特异性而常作为其辅助诊断工具,高CEA值是不良预后的标志。PSA:用于辅助诊断前列腺癌,并监测前列腺癌的治疗效果。这些肿瘤标志物在临床实践中具有重要的应用价值,准确的检测结果对于患者的诊断和治疗管理尤为关键。
在临床实验室检测过程中,分析前误差可能发生在样本采集、处理或运输阶段,从而导致分析结果错误。这些情况占所有检测误差的60-70%,其中大多数(约75%)因样本质量问题造成,如溶血或样本凝固。并且多在检测过程中被发现,临床实验室根据溶血程度决定是否拒收样本,或者在检测报告中备注样本质量说明(如“溶血可能影响检测结果”)并继续进行检测。然而,样本误识别性错误—尽管约占所有分析前错误的0.3%—但当一个患者的检测结果错误地移植到另一个患者时,可能导致严重的诊断和治疗事故。
为了避免分析前阶段差错,临床实验室研究人员在报告签发之前使用各种方法审核验证检验结果的准确性。其一的策略是差值检查(delta check)法,如果当前检测结果与上次检测结果之间的差异超过一定阈值,该方法会提醒实验室人员注意是否潜在错误发生。传统的差值检查方法通过识别与差值可信限偏离的结果来检验是否由于患者生物学变异或实验室仪器变化引起的问题。这种差值检查方法被认为在检测分析前错误(如样本误识别、样本污染和溶血)方面是有效的;然而,该方法的灵敏度仅约为20%。同样的研究证明,当为五种肿瘤标志物建立实用的差值检测限时,根据临床环境(不同的医院、实验室或检测条件)和检测项目不同,灵敏度为20-50%。为了解决这一问题,研究人员正在开发一种基于机器学习(ML)的新的差值检查方法,该方法已显示出比传统方法更好的性能。ML可以通过非线性学习机制学习复杂的关联和模式,这种方法能够检测出传统统计方法难以捕捉的细微和关联性变化。与传统方法不同,ML技术可以从数据分布和模式中学习,构建优化模型,帮助提高错误检测的准确性。尽管已有少数关于一般化学和常规血液学检测的基于ML的差值检查研究,但针对肿瘤标志物尚未有相似的报道。因此,本研究旨在开发和验证一种用于检测临床实验室样本误识别性错误的基于ML的差值检查方法。使用五种肿瘤标志物(AFP、CA19-9、CA125、CEA和PSA)的历史检测结果,开发了随机森林(RF)模型和深度学习模型,并将其性能与传统的差值检查方法(如DPC、absDPC和参考变化值RCV)进行了比较。
一、材料和方法
1. 数据收集:本研究使用的数据自2020年1月至2021年12月期间,从釜山国立大学医院、海云台白医院和Ilsan白医院的实验室信息管理系统(LIMS)中,回顾性地收集了五种肿瘤标志物(AFP、CA19-9、CA125、CEA和PSA)的检测结果。测试仪器为Roche Cobas C-8000。
收集的数据包括当前结果(当前测量结果)、最近一次结果(过去两年内最后一次检测的结果)、年龄、性别、申请科室、报告日期和患者分组,无一例患者缺失以上数据。在本研究中将最近一次和当前结果用作模型开发的输入数据。而诸如年龄、性别、申请科室和报告日期等变量未认定为可用输入数据。如此处理是因为这些因素被认为与样本误识别性错误无关,或者被认为不足以对样本识别构成任何影响。患者分组包括接受健康筛查的患者(H)、门诊患者(O)和急诊或住院患者(I)。剔除了超出分析系统测量区间(AMI)的检测结果。各项目的AMI分别为:AFP 0.908-1,210μg/L、CA125 0.6-5,000KU/L、CA19-9 0.6-1,000KU/L、CEA 0.2-1,000μg/L和PSA0.003-100μg/L。表1显示了本研究中使用的五种肿瘤标志物的数据集信息。开发集(D-set)包含前18个月(2020年1月至2021年6月)的179,929条记录,用于开发差值检查方法;测试集(T-set)包含最后6个月(2021年7月至2021年12月)的66,332条记录,用于评估差值检查方法。
表1. 数据集列表如下

注:AFP:甲胎蛋白;CA 19-9:糖类抗原19-9;CA-125:糖类抗原125;CEA:癌胚抗原;PSA:前列腺特异性抗原H:健康筛查;O:门诊患者;I:急诊或住院患者
2. 样本误识别性错误的整体检测流程:图1展示了模型开发和验证的整体过程。本研究采用RF和深度神经网络(Deep Neural Network,DNN)两种基于特征工程的ML算法构建二分类模型,用于样本误识别检测。其中,RF作为一种集成学习算法,通过构建多棵决策树进行特征选择和分类预测,在特征重要性分析中具有显著优势;DNN则通过多层非线性变换结构,能够自动提取数据的高阶特征表示,在处理复杂非线性关系方面表现出优异的性能。基于ML的样本误识别性错误检测方法的性能与传统的验证方法(如DPC、absDPC和RCV)进行了比较。所有模型均使用D-set进行开发,并使用T-set进行测试。ML模型的训练数据通过随机打乱当前一定百分比的结果来模拟“样本洗牌”既打乱样本顺序,而传统方法的差值检查限值则未使用样本洗牌的数据推导得出。ML模型的性能评估不考虑患者分组。传统模型的性能评估分为两个方式进行:第一:从所有D-set中推导差值检查限值,并应用于所有T-set,不涉及患者分组。第二:实施患者分组,从D-set中的H、O和I患者组中分别推导差值检查限值,并独立评估对应患者分组在T-set中的性能。图2展示了所提出的基于ML的模型与传统模型之间的比较研究。模型实现、预处理以及DPC、absDPC和RCV计算使用了Python 3.9(Python软件基金会)。此外,TensorFlow(版本2.14.0)、Keras(版本2.13.1)和scikit-learn(版本1.2.2)被用于RF和DNN模型的构建。
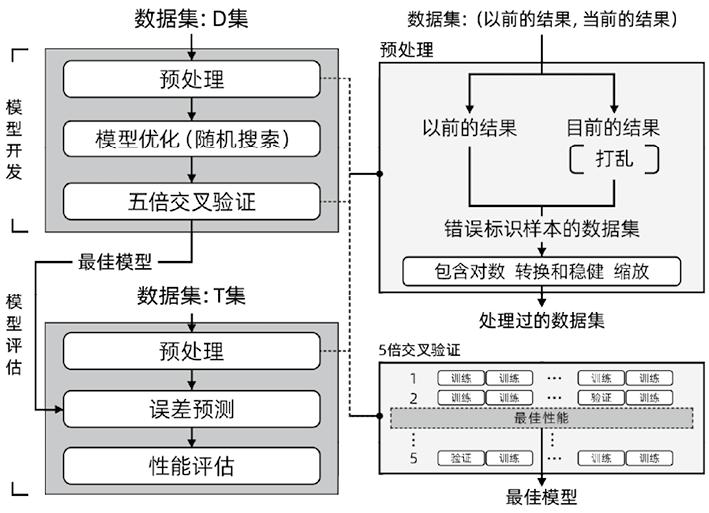
图1. 模型开发和评估的整体
3. 基于机器学习的差值检查模型:为了模拟样本误识别性错误,本研究在D-set中随机打乱了1%的测试结果。然后将这些被打乱的结果标记为“误识别”,用1表示;而正确排列的结果被标记为“已识别”,用0表示。输入数据进行了对数转换,以此减少极端值的影响并使数据正态化。对数转换是一种常见的预处理方法,用于在ML模型训练中处理连续数据。它特别适用于将偏态的分布数据转换为更接近正态分布数据,并通过改善输入数据的正态性来帮助训练更复杂的模型。此外还应用了稳健缩放(Robust Scaling)方法将每个特征的中位数(Q2,即第二四分位数)设置为0,并基于四分位距(IQR,即第1四分位数Q1和第3四分位数Q3之间的差值)进行归一化:归一化数学表达式=(原始值-Q2)/(Q3-Q1)。
在构建RF和DNN模型时,通过随机搜索优化了每个模型的超参数。在这个过程中,使用平衡准确率作为性能评估指标,以减轻分组不平衡的影响。接下来,进行了5倍交叉验证(5-fold cross-validation),以验证模型的泛化性能。在5倍交叉验证中,数据集被分为5个大小相等的子集(folds)。每次选择一个子集作为验证集,其余四个子集作为训练集,独立进行5次训练和评估,最终取平均值作为模型的整体性能。在评估过程中,具有最高受试者工作特性曲线下面积(AUROC)的子集所对应的模型被选为“最佳模型”。最后,通过将T-set应用于最佳模型,评估了模型的错误检测性能。
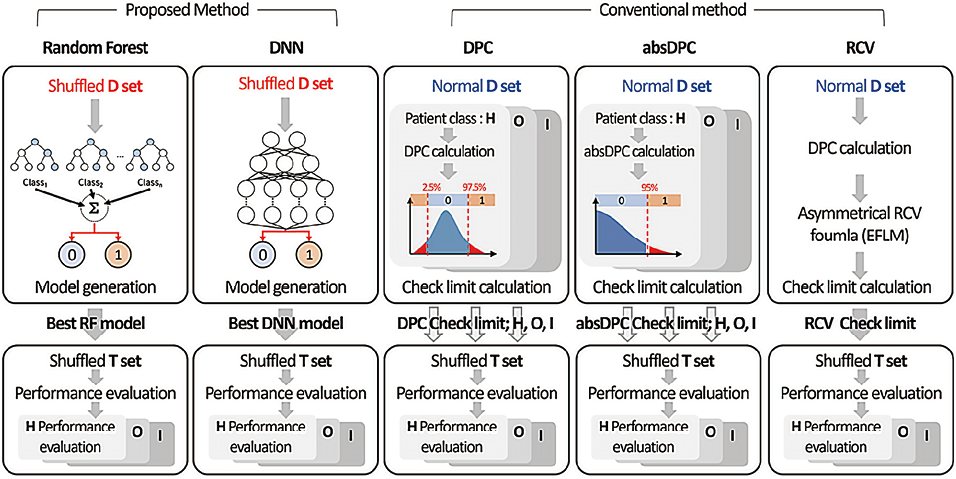
注:RF(随机森林),DNN(深度神经网络),DPC(百分比变化),absDPC(绝对值百分比变化),RCV(参考变化值);H(健康筛查),O(门诊患者),I(急诊或住院患者)。
图2. 基于机器学习的模型与传统模型之间的比较研究
4. 传统差值检查方法:传统差值检查使用DPC、absDPC和RCV确立的检查限值来进行的。具体计算方法如下:
(1)DPC(百分比变化):DPC是通过计算前后两次检测结果之间的变化比例,并将其除以前一次检测结果来得出的。公式如下:

absDPC(绝对值百分比变化):absDPC是DPC结果的绝对值,表示为:
absDPC=∣DPC∣ (公式2)
(2)RCV(参考变化值):RCV基于欧洲临床化学和实验室医学联合会(EFLM)的生物变异数据库,采用非正态数据处理工具即RCV公式进行推导。对于D-set中的每个H、O和I患者组,均为其构建相应的delta检查限值。DPC将该限值设定采用了双侧2.5%的百分位数范围,即排除数值分布的两端各2.5%的极端值,保留中间95%的数据范围作为有效区间,而absDPC则将该限值直接采用了95%的百分位数范围,即保留数值分布的95%数据范围,排除最高和最低的5%极端值。
为了评估ML模型的性能,本研究使用了置换检验(Permutation Test),该方法通过重复评估模型性能并在每次迭代中随机重新采集数据来获得平均性能。具体过程如下:置换检验:重复训练和验证:模型的训练和验证过程重复进行了1,000次,每次迭代中随机打乱1%的数据。目的:通过多次迭代,确保模型性能评估的稳定性和可靠性。传统方法的评估:使用包含1%样本误识别错误的T-set以DPC、absDPC和RCV(传统方法)评估样本误识别错误的检测性能。整体评估:最初使用从整个D-set推导出的差值检查限值对整个测试集进行评估。患者分组评估:针对测试集中各组患者(H、I和O),使用由各组患者对应的开发集中推导出的差值检查限值进行独立分析。
(3)性能指标:AUROC(受试者工作特性曲线下面积):作为模型鉴别能力的关键指标,AUROC值范围为0到1,值越高表示模型性能越好。平衡准确率(Balanced Accuracy):是灵敏度和特异性的平均值,能够提供更准确的模型性能评估,尤其是在各组分布不平衡的数据集中表现突出;它反映了模型在不同分组之间的平衡鉴别能力。灵敏度(Sensitivity):衡量模型正确检测真阳性的能力。特异性(Specificity):评估模型正确识别真阴性的能力。
二、结果
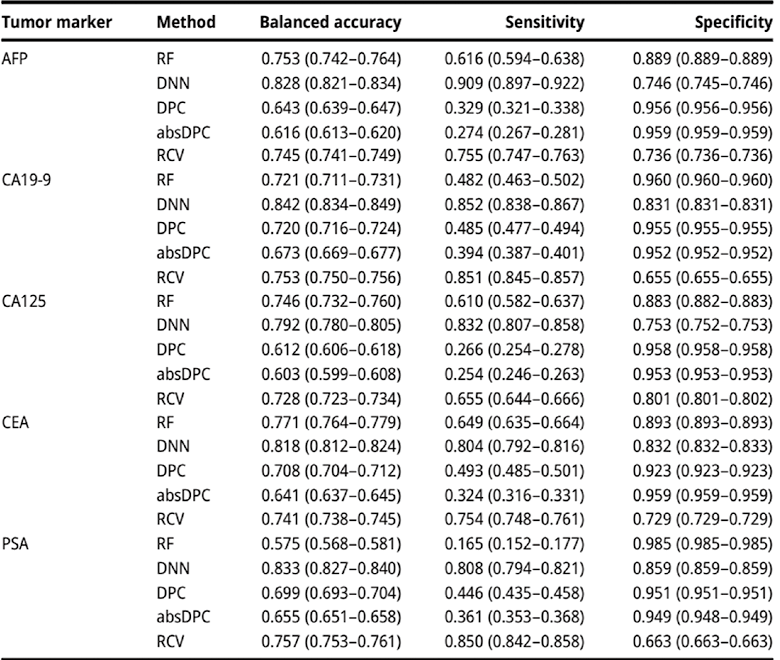
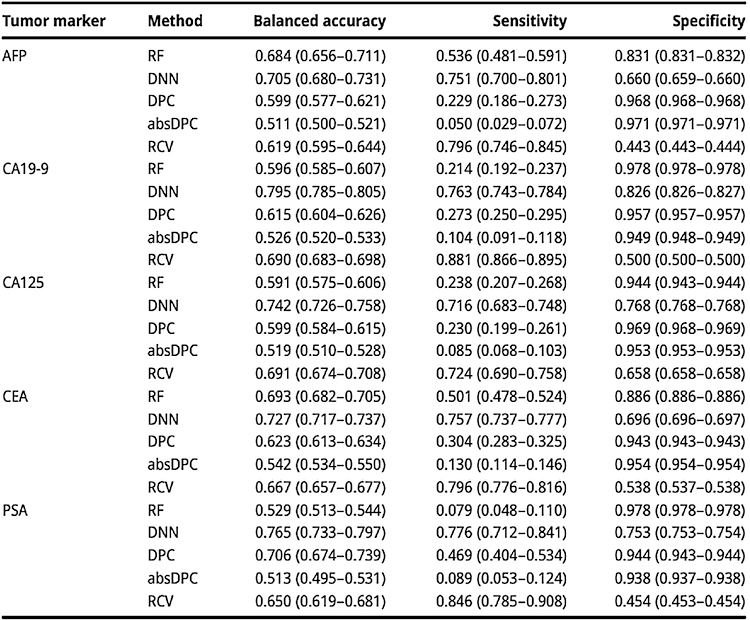
1. 差值检查方法的性能评估:图3展示了开发模型在样本误识别错误检测方面的性能。蓝色和红色实线:分别代表RF和DNN的平均ROC曲线。浅蓝色和浅红色区域:表示RF和DNN的标准偏差范围。DPC、absDPC和RCV方法学性能由每个符号表示,纵坐标轴代表灵敏度,横坐标轴代表特异性。RF模型:AFP、CA19-9、CA125、CEA和PSA,AUROC分别为0.791、0.816、0.751、0.797和0.787。DNN模型:各肿瘤标志物,AUROC分别为0.831、0.877、0.829、0.838和0.860。从AUROC比较看,DNN模型在所有肿瘤标志物上的性能优于RF模型。RF模型:比DPC和absDPC方法表现出更好的检测性能,但在大多数情况下不如DNN和RCV方法。DNN模型:在所有肿瘤标志物上都表现出最高的AUROC值,特别是对AFP、CA19-9、CA125、CEA和PSA的检测准确率分别为0.828、0.842、0.792、0.818和0.833,均高于其他方法。灵敏度:DNN模型的灵敏度也较高,分别为0.909、0.852、0.832、0.804和0.808,除了PSA外均优于其他方法。
表2展示了RF、DNN、DPC、absDPC和RCV方法在不同肿瘤标志物上的样本误识别性错误检测性能。RF在AFP、CA19-9、CA125、CEA和PSA的样本误识别性错误检测中,平衡准确度分别为0.753、0.721、0.746、0.771和0.575。然而,与RCV相比,RF在CA19-9和PSA上的表现更差,PSA的平衡准确度最低(0.575)。与此同时,DNN方法在AFP、CA19-9、CA125、CEA和PSA肿瘤标志物上的样本误识别性错误检测准确度分别为0.828、0.842、0.792、0.818和0.833,这些是所有方法中最高的;此外,灵敏度分别为0.909、0.852、0.832、0.804和0.808,除了PSA外,都优于其他方法。
表2. 在检测肿瘤标志物样本误识别性错误中每个差值检查模型的性能比较。平均值(95%置信区间)
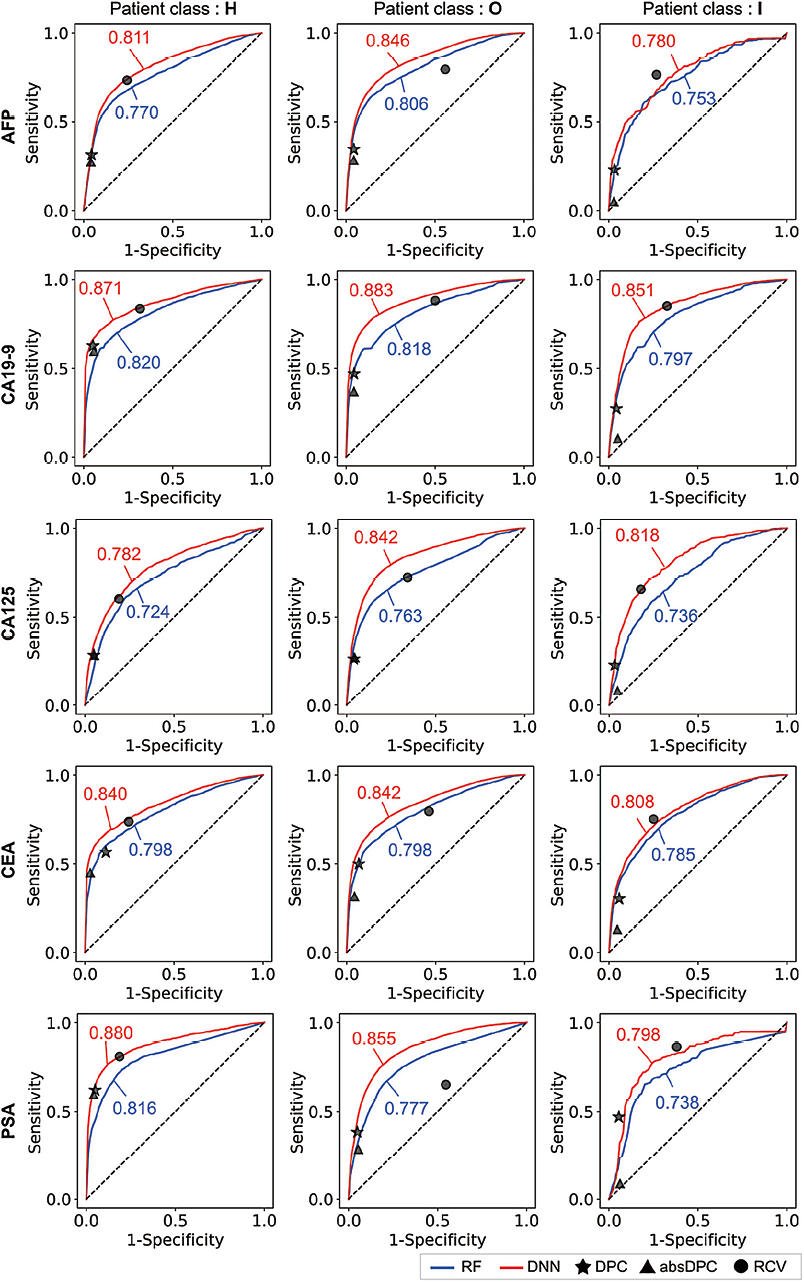
2. 按患者分组划分的差值检查方法的性能评估:图4展示了按患者分组(H、O、I)和肿瘤标志物(AFP、CA19-9、CA125、CEA、PSA)分类的各模型性能评估结果。每行肿瘤标志物,从上到下依次对应为AFP、CA19-9、CA125、CEA、PSA。每列从左到右依次对应为三组患者(H:健康筛查,O:门诊患者,I:急诊或住院患者)。蓝色实线:表示RF的ROC曲线。红色实线:表示DNN的ROC曲线。DPC、absDPC和RCV方法的评估结果纵坐标表示灵敏度,横坐标表示特异性。DNN模型:在所有肿瘤标志物和所有分组患者中表现最佳;但在急诊或住院患者(I类)中,其性能与RCV相似或略低。RF模型:在所有分组表现均不如DNN和RCV,并且与DPC和absDPC的表现类似。表格3-5展示了RF、DNN、DPC、absDPC和RCV在不同患者分组中的详细性能指标(AUROC、平衡准确率、灵敏度和特异性)。
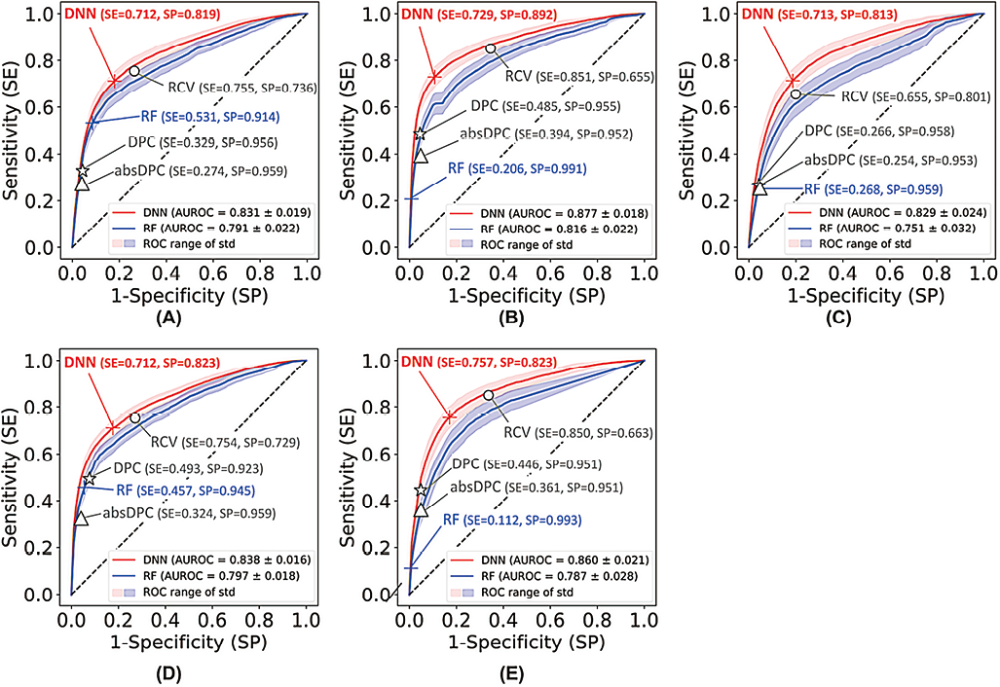
注:(A)AFP,(B)CA19-9,(C)CA125,(D)CEA,(E)PSA。图中的标记点代表RF、DNN、DPC、absDPC和RCV的最佳阈值。RF,随机森林;DNN,深度神经网络;DPC,变化百分比;absDPC,绝对变化百分比;RCV,参考变化值;SE,灵敏度;SP,特异性;ROC,受试者工作特征曲线。
图3. RF和DNN模型以及传统方法的ROC曲线
注:实线代表ROC曲线,数字代表AUROC值;每行为各肿瘤标志物;列代表各患者分组
图4. 根据患者分组基于机器学习的方法和传统方法的性能比较
三、讨论
在本研究中,我们为五种肿瘤标志物(AFP、CA19-9、CA125、CEA和PSA)开发了基于RF和DNN的差异检查方法,并评估了它们在检测样本误识别性错误方面的性能,将其与传统方法(如DPC、absDPC和RCV)进行了比较。这是首次针对肿瘤标志物测试开发基于ML的差异检查方法的研究。此外,我们使用了与之前研究相同的数据集进行模型开发,以确保与传统方法的平行对比。尽管灵敏度和特异性是评估模型性能的关键指标。然而优化两者之间的最佳平衡点面临复杂的挑战,偏重更高的灵敏度可能会增加假阳性率,导致不必要的重复测试或系统校正,增加实验室工作量;而侧重更高的特异性可能会增加假阴性率。因此,对临床实验室来说,至关重要的是确保两个指标都在可接受水平上,而不是偏向任何一个指标。值得注意的是,DNN的ROC曲线优于传统方法(见图3)。鉴于灵敏度和特异性取决于临界值,但最终由ROC曲线来决定,即使还需要对两者权重平衡,但DNN的性能仍被认为是优于传统方法的。然而,由于不同实验室对灵敏度和特异性的目标值存在差异性,临界值的优化需依据各实验室的具体规范要求进行相应调整。
DNN模型在检测样本误识别性错误方面的优越性能在于这两种模型基础工作原理的不同。DNN采用迭代算法对输入数据进行加权求和运算,通过非线性变换生成连续输出值,并基于预设的决策阈值对该输出值进行误差评估与校正。相比之下,RF依赖于对随机选择的特征子集进行连续分割并根据特定标准值预测因变量。鉴于差值检查法本质上是“分析两个数据之间的差异”,值得注意的是,与DNN不同,基于决策树的集成模型(如随机森林RF)采用基于特征绝对值的分割准则构建分类边界,而不对数据之间差异进行分析和比较。如果输入的数据范围广泛或多样,基于决策树的模型可能导致显著的性能改变,进而影响决策树的数量或深度。此外,当处理少量特征型数据时,由于随机性的选择过程,RF模型可能会导致过拟合或不稳定的预测结果。在本研究中,仅使用前后两次测试结果作为构建模型的数据,因此认为DNN在有限的特征性数据情况下提供了更稳健的性能。
DPC和absDPC通过使用特定患者群体的结果分布来统计差值检查限值,以此检测样本误识别性错误。对于非标准化或非相同检测系统的测试,测量结果会因实验室方法、试剂和校准材料制造商的不同而有所差异,特别是针对肿瘤标志物的检验尤其如此。差值检查限值因不同的实验室条件或患者的临床状况而不同。由于RCV是基于个体内变异性和实验室不精确性设定的,它们必须根据每个具体的临床条件进行调整。本文在按患者分组的基础上确定了DPC、absDPC和RCV的差值检测限,并应用于各组患者以评估样本误识别性错误的检测性能。RF和DNN模型在应用训练好的模型时未对患者分组。结果显示,即使未对患者分组实施优化,DNN在按患者分组评估时仍然优于传统的差值检查方法。然而,在急诊或住院患者(I类)中,DNN的表现与RCV相当或略差,这表明模型训练可能偏向健康筛查(H类)和门诊患者(O类),因为I类患者在训练数据中的比例较小(14,223/179,929≈7.9%)。RF模型的性能在各肿瘤标志物有所不同,特别是对CA19-9和PSA的性能较差。
ML方法与传统方法在不同患者分组上表现出显著的性能差异,这一现象值得关注,图5展示了五种肿瘤标志物在不同分组患者中的平衡准确率差异。所有模型的平衡准确率按H、O、I顺序递减。然而,传统方法在患者分组间的性能差异更为显著,这可能是由于统计模型对输入数据变异性的高度灵敏度所致,因为它们通过预设的固定参数来识别误差。相比之下,ML方法通过训练过程自主学习与样本误识别相关的潜在特征模式,其泛化能力不受患者分组的影响,因而对数据分布的变异表现出更强的稳健性。综上所述,基于机器学习的DNN模型不仅在差值检查方法表现最佳,而且对临床多种因素的变化具有更强的稳健性,可以在各种实验条件下灵活应用。基于上述研究结果可以得出结论,DNN有能力在基于一个实验设备检测结果开发的差值检查模型同样有效应用于其他实验设备。我们计划在未来的研究中进一步调查和分析DNN模型在这一领域的临床应用效果。
需要注意的是,本研究使用的数据是通过计算机模拟生成的,而非实际样本误识别数据。这种方法可以作为当前实验条件中误识别数据记录的一种可行性的替代方案。收集真实临床实验样本误识别数据将有助于了解影响样本误识别的各种因素,并通过采信其他数据(包括样本的运输和存储条件、样本的采集时间、样本的类型和容器等)改进误差检测性能。此外,本研究主要集中在内部验证,未包括泛化能力的验证。未来的研究计划通过外部验证来克服这一局限,使用来自多个机构的数据进行验证,这是临床推广应用前的重要步骤。
表3在分组H中,针对肿瘤标志物样本误识别性错误,每个差值检查模型的性能比较。基于RF和DNN的差值检查方法是使用1%随机打乱的总数据集(D-set)开发的,不考虑患者分组。传统的差值检查限值包括DPC、absDPC和RCV是使用来自患者分组H的未打乱的数据集(D-set)得出的。数字代表平均值(95%置信区间)

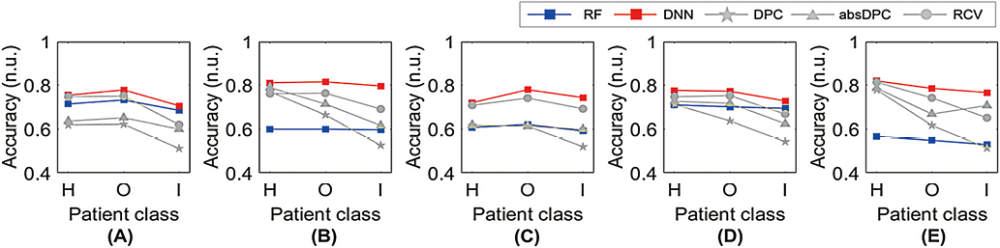
图5. 根据不同患者分组,对每种肿瘤标志物的平衡准确性进行比较
表5在患者分组I中,针对肿瘤标志物样本误识别错误,每个差值检查模型的性能比较。基于RF和DNN的差值检查方法是使用1%随机打乱的总D集开发的,不考虑患者分组。传统DPC、absDPC和RC的差值检查限值是使用来自患者分组I的未打乱的D集得出的。平均值(95%置信区间)
结论:本研究对临床实验室中最常用的五种肿瘤标志物开发了基于RF和DNN模型的差值检查方法,并评估了其在检测样本误识别性错误方面的性能,与传统差异检查方法进行了比较。综合灵敏度和特异性,结果显示,DNN模型在所有肿瘤标志物上均表现出最高的平衡准确率,表明它是用于临床实验室中最合适的差值检查方法。此外,DNN模型显示出凭借其仅通过单一整合数据集即可应用于多个特征性分组患者,显示出更强的稳健性和普适性。预计未来在临床实验室的多种检查场景中会得到广泛地应用;从而提升实验室的整体诊断质量和效率。![]()
编译节选自:Clin Chem Lab Med 2024; 62(7): 1421-1432


