


血清假性高钾修正的机器学习模型建立与应用评估

郑磊,医学博士,教授,博士生导师。现任南方医科大学南方医院检验科主任,广东省重大疾病快速诊断生物传感技术工程研究中心主任。2020年获国家杰出青年科学基金。现任国际细胞外囊泡学会执委、中华医学会检验分会常务委员、广东省医师协会检验医师分会主任委员、广东省医学会检验分会第十届主任委员等学术职务。主要研究方向为重大疾病标志物发现与检测新技术研究、血栓与止血实验诊断、检验教育信息化研究等。承担国家自然科学基金、美国AACC POCT项目、省部级科研课题十余项,以通讯或第一作者身份在Materials Horizons、Nano letters、Adv Funct Mater、Biosens Bioelectron等国际知名期刊上发表SCI论文40余篇,其中I区论文12篇,国家发明专利6项。获广东省教学成果一等奖2项,任副主编出版教材及专著8部。

杨超,南方医科大学南方医院主管技师,医学硕士。长期从事临床检验以及检验相关系统维护和研发工作,熟悉多种编程语言和人工智能算法。获得软件著作权多项,发表SCI文章5篇。
临床上一般采用血清钾反映我们机体内的钾离子浓度,正常条件下,血浆钾要比血清钾低0.4mmol/kg左右。当钾离子的平衡紊乱时,可能会危及生命。当血钾浓度高于5.5mmol/L时,即可诊断为高钾血症,而高于7.0mmol/L则为严重高钾血症[1]。高钾血症是一种可能危及生命的电解质异常的病理生理状态[2],高钾血症患者可表现出一系列的神经肌肉症状,如肌无力、肌肉酸痛、震颤。高血钾可抑制神经和神经肌肉之间兴奋的传递,并可改变心肌膜电位,出现心动过缓、室颤等心律失常的表现[3]。高钾血症是机体病理或生理条件下所导致的。而假性高钾血症的出现,会干扰临床医生对高钾血症的鉴别。
假性高钾血症最早是在1955年由Hartmann和Mellinkoff两人所提出。其定义为血浆钾浓度正常而血清钾浓度升高,且血清钾大于血浆钾浓度0.4mmol/L[4],但却不伴有造成高钾血症的病因和临床表现,心电图也无明显异常。假性高钾血症并不能真实地反映机体内钾离子的浓度,导致假性高钾血症的原因有很多,如体内或体外细胞破裂、溶血、白细胞和血小板数目增多[5]、采血过程握拳、使用止血带等都会导致血清钾升高[6]。如果不能正确认识和判别假性高钾血症,便可能误导临床医生的判断,错误的降钾易诱导低钾血症和心律失常的发生,危及生命,因此,高钾血症和假性高钾血症的鉴别尤为重要。
一般情况下,有典型临床症状的为高钾血症患者,假性高钾血症患者无任何临床表现。其次,心电图也可以作为两者的鉴别依据之一。再者,还可以同时对血清钾和血浆钾进行测定。当血清钾和血浆钾均升高的时候,为高钾血症;当血清钾升高而血浆钾正常的时候,为假性高钾血症。但由于高钾血症患者并非都具有明显的临床表现,且临床症状无特异性表现,因此特别容易被原发疾病所掩盖[7]。尽管其心电图变化具有特异性,有利于诊断和治疗,但研究结果表明,仅有不足50%的患者心电图发生特异性改变[8]。
血小板增多是指血小板计数超过450×109/L。血小板计数在450~700×109/L为轻度,700~900×109/L为中度,900~1000×109/L为重度,超过1000×109/L为极重度血小板增多[9]。按其原因可分为原发性、继发性和假性[10]。血小板增多症常见于急性或慢性炎症、缺铁性贫血、肿瘤患者以及脾切除术后的患者。原发性血小板增多多见于骨髓增生性疾病,如原发性血小板增多症、慢性粒细胞白血病、真性红细胞增多症等。血小板增多时,血小板大量聚集,导致血小板破坏,细胞内钾离子大量进入血清中造成血清钾假性升高。有研究者对血小板增多患者的血清钾与血浆钾差异值DK和血小板之间的关系进行研究,得到一种修正钾值的线性计算公式,从而估算真正的血钾值[11]。但其没有全面系统地考虑所有因素对钾离子的影响,如白细胞等其他因素。同时,血小板与DK本身可能并不存在线性关系,而是多因素影响下的非线性关系。
近年来,随着信息技术的不断发展,机器学习模型越来越多地应用于医学领域。机器学习模型可以对数据进行快速准确地分析,从而对疾病进行预测、诊断分级、辅助临床决策等。随机森林是一种基于多棵决策树对样本进行训练的算法,训练后的模型可以对样本进行定性分类或定量预测。它具有抗噪性能好,鲁棒性强的特点,确保其具有很强的泛化能力。同时,训练参数更少,训练时间更短,稳定性更强也成为了其优势。即便有小部分样本数据丢失,对该模型的总体精度仍然影响不大[12]。支持向量机是根据监督学习方式将数据进行分类的一种线性分类器。训练的样本空间需是线性的是其分类的基础。但考虑到临床工作中数据的复杂性,因此必须借助于核函数来使得数据满足条件。核函数分为线性核函数(linear)、高斯核函数(rbf)等[13]。可应对高维数据集和低维数据集,即使数据集中样本特征的测度比较接近,其也能驾驭,适用于小样本、多维度、非线性的情况[14]。但其对数据预处理和参数调节的要求很高。多层感知器是一种前向反馈的多层神经网络,其利用神经元来对数据建立预测模型。优势在于对数据分布没有限制,善于发现数据之间错综复杂的联系,在非线性数据的处理方面优于传统的统计学方法[15]。
因此,本研究拟训练机器学习模型,根据患者的一些基本信息,临床诊断以及检测指标,使其能够识别患者是否为假性高钾血症,同时能够对血清假性高钾进行修正。
一、研究对象与方法
(一)研究对象收集
2021年8月至2022年3月在南方医科大学南方医院检验科门急诊组收集同一患者凝血用的血浆、生化用的血清、血常规用的全血以及其临床资料。
(二)试剂与仪器
1. 主要试剂:各检测项目所需要的主要试剂见表1。
2. 主要仪器:见表2所示。
(三)研究方法
1. 血细胞分析:采用全自动模块式血液体液分析仪XN-10,使用含有EDTA-K2抗凝剂的血细胞分析专用采血管,采集静脉血2ml,充分颠倒混匀,于2h内尽快上机检测。记录患者的WBC、LYM、NEU、MONO、EOS、BASO、LYM%、NEU%、MONO%、EOS%、BASO%、RBC、HGB、HCT、MCV、MCH、MCHC、RDW-SD、RDW-CV、PLT、PCT、MPV、PDW-SD、P-LCR、IG#、IG%、HFLC%、NEWX%、NESFL、LYZ和MicroR共31个指标的数值。
2. 血清钾离子浓度:采用罗氏Cobas c8000生化分析仪,使用含有促凝剂和惰性分离胶的生化分析采血管采集2ml静脉血,采集后迅速颠倒混匀,室温下静置30min,3000r/min离心5min分离血清,尽快上机检测血清中钾离子浓度、钠离子浓度以及氯离子浓度。
3. 血浆钾离子浓度:采用罗氏Cobas c8000生化分析仪,使用含有枸橼酸钠为抗凝剂的生化分析采血管,采集2ml静脉血,采血后迅速颠倒混匀,在3000r/min下离心5min分离血浆,记录标本量,并尽快上机检测血浆中钾离子浓度、钠离子浓度以及氯离子浓度。
4. 计算DK值:DK(K-difference)=血清钾-血浆钾,以此作为假性高钾血症的判断指标。DK>0.4mmol/L即可判断为假性高钾血症。
5. 统计学方法:统计数据使用SPSS统计软件包处理,进行相关分析、直线回归分析、逐步回归分析,筛选出有意义的自变量。
6. 机器学习模型的建立与验证:使用Python机器学习库建立和验证模型。数据集由271例患者37个变量构建而成。按照2:1的比例将整个数据集随机划分成训练组和验证组。训练数据集将用于不同机器学习模型的构建。判断是否存在假性高钾血症的标准为血清钾和血浆钾差值>0.4mmol/L。在建模过程中,使用三折交叉验证优化模型的超参数(整个训练集随机划分成3等份,2份用于训练,1份用于验证,交叉3次),从而确定模型的预测性能。采用当前常用的机器学习方法(包括RF、SVM、MLP)来构建对假性高钾血症的识别以及对真实血浆钾的预测模型。利用AUC、敏感性(Sensitivity)、特异性(Specificity)以及皮尔逊相关系数(PCC)、决定系数(R2)、平均绝对误差(MAE)作为指标来评价模型的预测效能。
二、研究结果
(一)数据收集
本研究收集了2021年8月至2022年3月在南方医科大学南方医院就诊的271例患者,男性147例,年龄(52.2±19.7)岁;女性124例,年龄(47.6±18.0)岁。血小板数为(244.0±176.4)×109/L,白细胞数为(12.2±19.4)×109/L。
(二)数据分析
1. 血小板数量与血清钾以及血浆钾的直线回归分析:经分析,血小板数量(x)与血清钾(y)的回归方程为y=0.001x+4.032(R2=0.271,P<0.001)。血小板数量(x)与血浆钾(y)的回归方程为y=-40.28x+401.1(R2=-0.013,P=0.062)。见图1,2。说明血小板数量与血清钾之间存在相关关系,但R2值小,预测效果不佳(P<0.05),而与血浆钾之间无相关关系(P>0.05)。
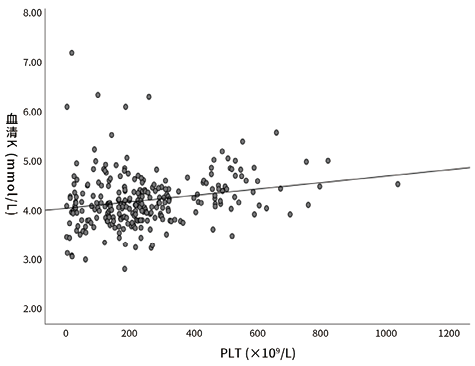
图1. 血小板数量与血清钾直线回归分析的结果
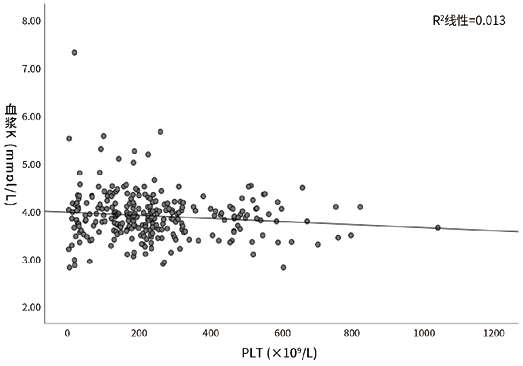
图2. 血小板数量与血浆钾直线回归分析的结果
2. DK值与相关检测指标:血清Cl、血清Na、凝血标本量、WBC、LYM、NEU、MONO、EOS、BASO、LYM%、NEU%、MONO%、EOS%、BASO%、RBC、HGB、HCT、MCV、MCH、MCHC、RDW-SD、RDW-CV、PLT、PCT、MPV、PDW-SD、P-LCR、IG#、IG%、HFLC%、NEWX%、NESFL、LYZ、MicroR和年龄多重相关分析结果见表3。
表3. DK值与各个测试项目多重回归分析结果
项目 | r值 | P值 |
PLT | 0.556 | <0.001* |
PCT | 0.542 | <0.001* |
MCHC | -0.286 | <0.001* |
血清Cl | -0.271 | <0.001* |
血清Na | -0.235 | <0.001* |
BASO% | 0.23 | <0.001* |
MCH | -0.228 | <0.001* |
EOS | 0.224 | <0.001* |
NEU | 0.172 | 0.005* |
HGB | -0.167 | 0.006* |
MicroR | 0.147 | 0.015* |
EOS% | 0.13 | 0.033* |
HCT | -0.128 | 0.035* |
NESFL | -0.115 | 0.06 |
MCV | -0.114 | 0.061 |
项目 | r值 | P值 |
凝血标本量 | 0.107 | 0.08 |
P-LCR | -0.101 | 0.099 |
MONO% | 0.086 | 0.158 |
RDW-CV | 0.086 | 0.159 |
BASO | 0.075 | 0.22 |
RBC | -0.075 | 0.217 |
LYM | -0.07 | 0.252 |
LYM% | -0.068 | 0.263 |
LYZ | 0.059 | 0.331 |
PDW-SD | -0.055 | 0.368 |
IG# | 0.052 | 0.393 |
WBC | 0.049 | 0.42 |
RDW-SD | 0.03 | 0.629 |
MPV | 0.029 | 0.63 |
HFLC% | -0.026 | 0.67 |
年龄 | 0.012 | 0.847 |
IG% | -0.012 | 0.849 |
MONO | -0.006 | 0.918 |
NEU% | 0.005 | 0.939 |
NEWX% | 0.001 | 0.992 |
注:DK值(K-difference)=血清钾-血浆钾,*P<0.05
DK值和各个测试指标多重相关性分析表明,PLT与DK值的相关系数值r=0.556(P<0.001),PCT与DK值相关系数r=0.542(P<0.001),MCHC与DK值的相关系数值r=-0.286(P<0.001),血清Cl与DK值的相关系数值r=-0.271(P<0.001),血清Na与DK值的相关系数值r=-0.235(P<0.001),BASO%与DK值的相关系数值r=0.230(P<0.001),MCH与DK值的相关系数值r=-0.228(P<0.001),EOS与DK值的相关系数值r=0.224(P<0.001),NEU与DK值的相关系数值r=0.172(P=0.005),HGB与DK值的相关系数值r=-0.167(P<0.006),MicroR与DK值的相关系数值r=0.147(P=0.015),EOS%与DK值的相关系数值r=0.130(P=0.033),HCT与DK值的相关系数值r=-0.128(P=0.035),以上指标与DK值有相关关系,差异有统计学意义(P<0.05)。除此之外,凝血标本量、WBC、LYM、MONO、BASO、LYM%、NEU%、MONO%、RBC、MCV、RDW-SD、RDW-CV、MPV、PDW-SD、P-LCR、IG#、IG%、HFLC%、NEWX%、NESFL、LYZ和年龄与DK值并无相关关系,差异均无统计学意义(P>0.05)。
3. 逐步分析法进一步筛选自变量:DK值作为因变量,对以上具有相关关系的13个变量进行逐步回归分析,筛选出更有意义的自变量。结果表明,PLT、HGB、HCT、血清Na为更有意义的自变量,逐步回归分析筛选变量的结果见表4。
表4. 逐步回归分析筛选变量的结果
指标 | 未标准化系数B | 标准误差 | 标准化系数Beta | P值 |
PLT | 0.001 | <0.001 | 0.496 | <0.001 |
HGB | -0.012 | 0.004 | -1.028 | 0.004 |
血清Na | -0.010 | 0.003 | -0.170 | 0.001 |
HCT | 3.341 | 1.407 | 0.840 | 0.018 |
4. 识别假性高钾模型的构建:为了准确识别假性高钾血症患者,本文将所有变量纳入模型的构建中,用三类机器学习模型(MLP、RF、SVM)进行识别,其中一组数据的ROC曲线见图3。从表5三类模型的表现可以看出,三类模型的特异性均在0.8以上,预测效果良好。敏感性最高的为RF和SVM-linear,均为0.750。三类模型的AUC值均在0.7以上,AUC值最高的是RF,达到0.814,说明RF在识别假性高血钾的效能方面优于另外两类预测模型。RF模型各个指标的权重见图4。
注:(a)多层感知器;(b)随机森林;(c)线性支持向量机;(d)高斯核函数支持向量机
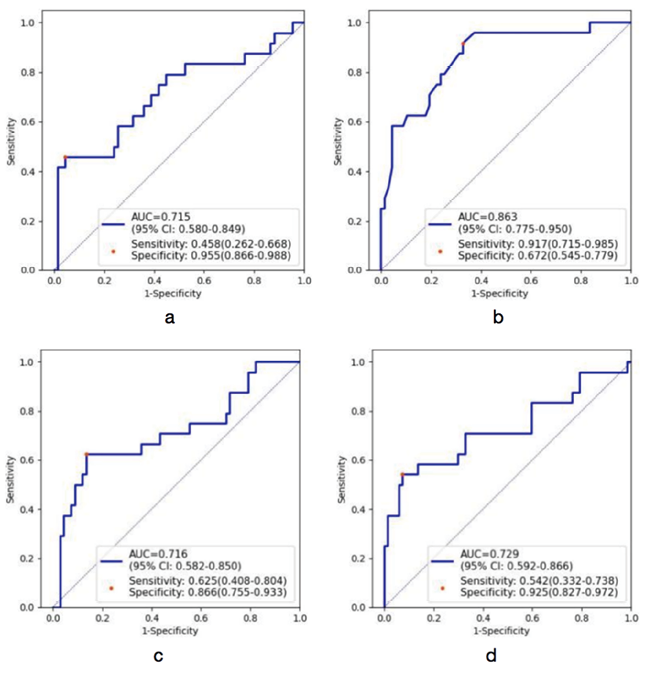
图3. 三类模型的受试者工作特征曲线
表5. 识别假性高血钾的模型的表现
Machine learning model | AUC | Sensitivity | Specificity |
Multilayer perceptron | 0.747±0.028 | 0.555±0.109 | 0.884±0.089 |
Random forest | 0.814±0.041 | 0.750±0.118 | 0.815±0.101 |
Support vector machine (linear) | 0.790±0.052 | 0.750±0.090 | 0.804±0.051 |
Support vector machine (rbf) | 0.718±0.028 | 0.528±0.020 | 0.940±0.012 |
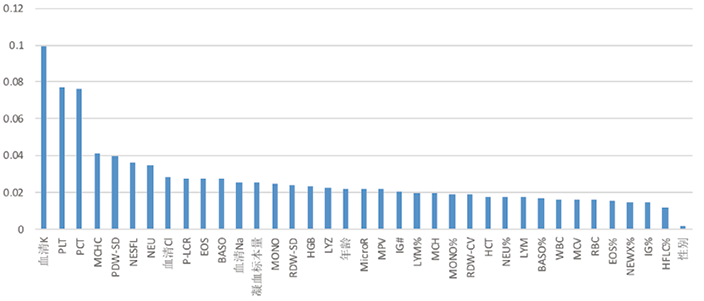
图4. 识别假性高血钾随机森林模型中各指标的权重
5. 血清钾的修正模型的构建:为了预测假性高钾血症患者真正的血钾浓度,本文构建了三类机器学习模型用于预测(MLP、RF、SVM)。采用皮尔逊相关系数(PCC)、决定系数(R2)、平均绝对误差(MAE)三个指标作为评价的依据。各类模型一组数据的预测和实际结果的拟合效果见图5,各类模型的表现见表6。可见,RF在PCC和MAE两个指标上的表现明显优于MLP、SVM-linear和SVM-rbf,在R2的表现上仅略逊于SVM-linear,说明对真正血浆钾浓度预测的问题上,RF优于其他两类模型。
注:(a)多层感知器;(b)随机森林;(c)线性支持向量机;(d)高斯核函数支持向量机
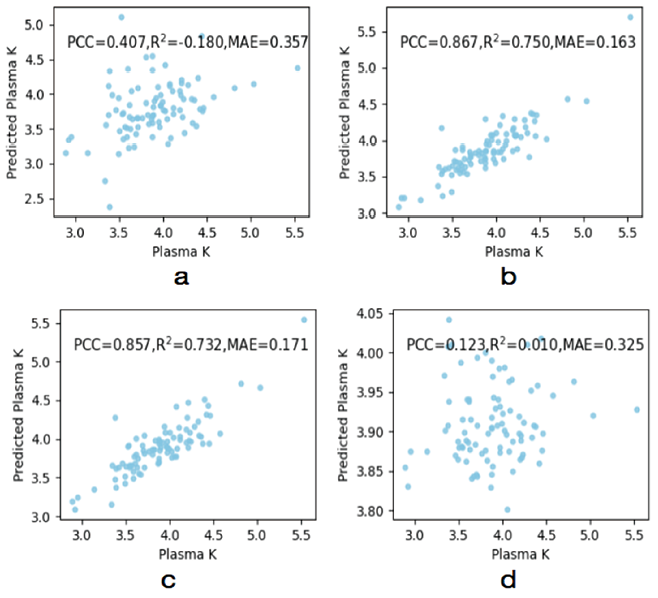
图5. 三类模型的拟合效果散点图
表6. 不同机器学习算法预测血浆钾的表现
Machine learning model | PCC | R2 | MAE |
Multilayerperceptron | 0.345±0.127 | 0.213±0.175 | 0.374±0.050 |
Randomforest | 0.840±0.019 | 0.692±0.042 | 0.189±0.030 |
Supportvectormachine (linear) | 0.362±0.352 | 0.706±0.069 | 0.241±0.050 |
Supportvectormachine (rbf) | 0.072±0.037 | -0.025±0.032 | 0.352±0.029 |
三、分析与讨论
血钾是维持机体内电解质平衡的重要离子之一。当血清钾浓度高于5.5mmol/L时称为高钾血症。高钾血症会导致一系列严重的临床反应,如软弱无力、面色苍白、肌肉酸痛、四肢湿冷。严重者还会出现心律失常,危及生命,因此,临床医生必须及时发现,并给予相应的治疗。而假性高钾血症并不能真实反映血钾浓度,其血浆钾浓度正常而血清钾浓度升高。如果未能及时发现假性高钾血症,容易导致临床医生误诊误治。由于高钾血症患者并非都有明显的临床表现和特异性的心电图变化,因此本研究通过开发一个机器学习模型,利用各种检验指标、临床信息等去预测真实的血钾值具有一定的临床意义。
瞿晓媛[16]团队对血小板增多患者的血清钾和血浆钾之间的差异值(DK)和血小板之间的关系进行探索,从而得到修正血清钾的计算公式。但其团队只探究了高血小板和DK值的关系,并未分析低血小板患者DK值和血小板的关系,且该公式在临床实际应用时使用繁琐、准确率不高,因此,本文沿用DK值这一指标与更多因素进行相关性分析、直线回归分析、逐步回归分析,找出相关性更强的指标。同时,将低血小板患者和正常血小板患者纳入分析,更全面地探究血小板与DK值的关系。
本文构建了机器学习模型用于识别假性高钾血症,采用常用的三种机器学习算法建立模型并对其进行评估。实验室结果显示,随机森林模型与多层感知器、支持向量机相比获得了更好的表现。AUC达到了0.814。可见随机森林的性能优于其他两类。尽管机器模型的性能仍然不够理想,但能通过提高其对假性高钾的敏感度,来对临床起到预警和提示的作用。后续仍需要对其进一步探索。
修正公式仅仅利用了高血小板与DK值的关系得出,本研究通过开发预测真实血浆钾的机器学习模型,能够综合多种影响因素更全面更系统地来预测指标,采用常用的三种机器学习算法建立模型并对其评估。与多层感知器、支持向量机相比,随机森林的PCC为0.840,表现优于其他机器模型,可见随机森林能较为良好地预测真实血浆钾浓度。修正模型能够在识别血清假性高钾模型预警时,给予临床工作人员一个参考,有助于临床医生进一步的决策和治疗。但三类修正模型总体性能仍不理想,后续需要通过进一步的探索来对模型优化。
在大数据时代,医学领域对数据分析的需求与日俱增。通过机器学习对疾病进行预测和分级成为主要的推动力。而获取更多的训练数据是提高模型性能的一种明显而有效的方法。更多的训练数据能使模型获得更高的准确率。本研究仅收集271例患者的数据,样本量较少,后续可收集更多样本数据来对模型进行训练调优。同时,本研究仅收集了南方医科大学南方医院的患者数据,缺乏外部验证,后续可通过收集多家医院的数据,使训练出的机器学习模型具备更好的泛化性。
![]()
参考文献
吕敏, 刘建军, 王媛媛, 等. 机体血钾异常的诊治及临床应用中的风险防控[J]. 海峡药学, 2020, 32(11): 105-109.
Dépret, Peacock WF, Liu KD, et al. Management of hyperkalemia in the acutely ill patient[J]. Annals Intensive Care, 2019, 9(1).
童岷奎, 叶蕾. 床边持续静-静脉血液滤过抢救ICU重度高血钾的有效性及对患者生命体征的影响[J]. 中国医学创新, 2021, 18(23): 39-42.
onuigbo M, Sherman S, Tan H. Mo218 alternating episodes of true hyperkalemia and pseudohyperkalemia in adult sickle cell disease-a nephrologist's dilema[J]. Nephrol Dial Transplantat, 2021, 36 (Supplement 1).
Bnaya A, Ruchlemer R, Itzkowitz E, et al. Incidence, risk factors, and recognition of pseudohyperkalemia in patients with chronic lymphocytic leukemia[J]. Inter J Hematol, 2021, 114(1): 1-7.
El Osama S,Rein Joshua L,Siddhartha K,et al. Reverse pseudohyperkalemia is more than leukocytosis: a retrospective study[J]. Clin Kidney J, 2021, 14(5): 1443-1449.
张晓明. 高血钾致房性心动过速伴巨大高尖T波1例[J]. 临床心电学杂志, 2017, 26(5): 369-370.
Zhao R, Hao X, Wang F, et al. The characteristic and dynamic electrocardiogram changes on hyperkalemia in a hemodialysis patient with heart failure: a case report[J]. Geriatr Cardiol, 2022, 19(2): 163-166.
Clemens Stockklausner CM, Duffert H,Cario R, et al. Kulozik. Thrombocytosis in children and adolescents-classification, diagnostic approach, and clinical management[J]. Annals Hematology, 2021, 100(7): 1-19.
Oscar B, Takaki A, Bertrand B, et al. Isolated congenital asplenia: An overlooked cause of thrombocytosis. [J]. Amer J hematol, 2022.
瞿晓媛, 徐益恒, 邰文琳, 等. 血小板增多导致血清假性高钾的修正[J]. 昆明医科大学学报, 2020, 41(5): 125-129.
陈海洋, 孟令奎, 周元. 基于随机森林的遥感影像雪冰云信息检测方法[J/OL]. 测绘地理信息, 2022(2): 105-110.
吴尚智, 王旭文, 王志宁, 等. 利用粗糙集和支持向量机的银行借贷风险预测模型[J]. 成都理工大学学报(自然科学版), 2022, 49(2): 249-256.
赵敬川, 赵吉宾, 李论, 等. 基于支持向量机的复杂曲面磨削去除量预测[J]. 组合机床与自动化加工技术, 2021, (11): 58-61.
肖淑玉, 高静, 孙志谦, 等. 多层感知器神经网络模型对职业性煤工尘肺发病预测研究[J]. 中国职业医学, 2021, 48(1):19-25.


