


基于机器学习算法结合血清学标志物的肺癌病理分型诊断模型建立

李波,医学博士,副主任医师,硕士研究生导师。现任解放军总医院第五医学中心检验科副主任,中国合格评定国家认可委员会(CNAS)技术评审员,中国医疗保健国际交流促进会基层检验技术标准化分会常务委员兼秘书长,中华医学会病毒学分会青年委员、《国际检验医学杂志》审稿专家。长期从事肝癌肿瘤标志物研究和新突发传染病病原快速诊断技术研究。承担首都临床特色应用研究专项、全军医学科技青年培育计划等多项课题,在Mol Biol Evol、BMC Infectious Diseases等国际期刊发表SCI论文12篇,其中以第一作者发表SCI论文6篇;中文核心期刊论文25篇;担任副主编出版专著1部,参编5部;获计算机软件著作权2项。获得军队科技进步一等奖、医疗成果二等奖、三等奖各1项。

肖英琪,理学学士,解放军总医院临床检验诊断学硕士研究生在读。本科毕业于潍坊医学院,三次获得优秀学生奖学金。
【摘要】目的 采用多种机器学习算法,结合临床常用的血清学标志物,建立可用于肺癌病理类型诊断的分类数学模型。方法 通过解放军总医院第五医学中心的电子病历系统,收集780例经过明确病理诊断的肺癌患者数据,采用R语言caret函数包进行数据处理和分析,建立广义线性(GLM)、随机森林(RF)、神经网络(NN)、支持向量机(SVM)、梯度提升器(GBM)分类模型,用于鉴别诊断肺癌的病理类型,并对构建的模型进行验证和评价。结果 5种分类模型对小细胞肺癌(SCLC)和非小细胞肺癌(NSCLC)的诊断准确率分别为91.42%、94.85%、93.13%、91.42%和94.42%;敏感度分别为65.31%、83.67%、87.76%、69.39%和83.67%;特异度分别为98.37%、97.83%、94.57%、97.28%和97.28%;AUROC分别为0.9359、0.9582、0.9576、0.9346和0.9562。对肺腺癌(LUAD)和鳞癌(LUSC)的诊断正确率分别为83.61%、80.87%、70.49%、77.60%和82.51%;敏感度分别为94.53%、92.19%、92.97%、93.75%和92.19%;特异度分别为58.18%、54.55%、18.18%、40.00%和60.00%;AUROC分别为0.8608、0.8614、0.7059、0.8193和0.8649。结论 利用机器学习算法建立的肺癌病理类型诊断模型具有较高的敏感度和特异度,可作为辅助诊断工具提高临床病理诊断的准确性,减少有创性检查的使用。
【关键词】人工智能;机器学习;肺癌诊断
根据2019年美国癌症协会及我国卫健委2015年发布的统计数据,肺癌是导致癌症患者死亡的首要原因[1]。肺癌在病理上可分为非小细胞肺癌(Non-small cell lung cancer,NSCLC)和小细胞肺癌(Small-cell lung cancer,SCLC),其中NSCLC占所有肺癌的80%~85%。NSCLC主要分为3种类型:肺腺癌(Lung adenocarcinoma,LUAD)、肺磷癌(Lung squamous cell carcinoma,LUSC)和大细胞癌(Large cell lung carcinoma,LCLC)。肺癌的治疗方式与其病理类型密切相关,其中分子靶向治疗对部分未吸烟的年轻肺腺癌患者有较好的治疗效果,肺鳞癌患者则多用手术治疗,小细胞癌患者大多选择化疗。因此,在临床上肺癌的病理类型精准诊断对患者治疗方式的选择及预后至关重要[2-3]。人工智能(Artificial Intelligence,AI)是研究、开发用于模拟、延伸和扩展人的智能的理论方法、技术及应用系统的一门新的技术科学[4]。机器学习(Machine Learning,ML)是AI技术的一个分支,已广泛用于疾病的诊断、分类及预测。既往研究结果表明,联合使用多种生物标志物及临床指标可以极大地提高诊断准确性[5]。采用ML技术,并通过结合多种生物标志物构建用于模式识别的数学模型,预测或诊断新的临床样本和患者,则有助于提高肿瘤等疾病的诊断准确率[6,2]。在本研究中,我们拟利用R语言的Caret函数包建立5种肺癌病理鉴别诊断模型,并对建立的模型进行性能评价和样本验证。
一、研究对象与方法
(一)研究对象
1. 样本来源:通过电子病历系统收集2015年1月至2020年12月解放军总医院第五医学中心收治的肺癌患者共计2000例,剔除数据不全或不符合条件的病例,最终纳入研究样本共780例,其中男526例,女254例,年龄26~85岁。所有病例均经肺组织活检确定病理分型,其中NSCLC 616例(79%),SCLC 164例(21%)。616例NSCLC中,LUAD 427例(54.8%),LUSC 186例(23.8%),LCLC 3例(0.38%)。
2. 纳入与排除标准:纳入标准:经肺组织活检确诊为肺癌者;数据资料齐全可用于后续数据分析。排除标准:转移性肺癌者;合并其他类型传染病或者系统性疾病者,如肺炎、心血管疾病和造血系统疾病等;良性肺结节者;指标检测前接受过放、化疗或手术治疗者。
(二)研究指标
选择30个血液生化、免疫学指标和性别、年龄作为研究指标,包括性别、年龄、癌胚抗原(CEA)、细胞角蛋白21-1(CYFRA21-1)、神经元特异性烯醇化酶(NSE)、胃泌素释放肽前(ProGRP)、鳞状细胞癌抗原(SCC)、总蛋白(TP)、白蛋白(ALB)、丙氨酸氨基转移酶(ALT)、天门冬氨酸氨基转移酶(AST)、总胆红素(TBil)、直接胆红素(DBil)、γ-谷氨酰基转移酶(GGT)、碱性磷酸酶(ALP)、乳酸脱氢酶(LDH)、肌酸激酶(CK)、肌酐(CRE)、尿酸(UA)、尿素氮(URE)、血糖(GLU)、白细胞总数(WBC)、中性粒细胞百分比(E)、淋巴细胞百分比(LYM)、血小板计数(PLT)、血红蛋白(HB)、红细胞比积(HCT)、凝血酶原时间(PT)、活化部分凝血活酶时间(APTT)、纤维蛋白原(Fbg)。
(三)模型的建立及评价
采用R语言caret函数包进行数据处理和分析。5种监督学习算法用于模型的建立和验证,包括广义线性(Generalized Linear Models,GLM)、随机森林(Random Forests,RF)、神经网络(Neural Network,NN)、支持向量机(Support Vector Machines,SVM)、梯度提升器(Gradient Boosting Machine,GBM)。
(四)统计学分析
采用GraphPad Prism 9软件和R Studio软件进行统计学分析及统计图绘制。采用ROC曲线、正确度、敏感度、特异度、阳性预测值、阴性预测值、Kappa值等指标对模型的诊断效率进行评价。
二、研究结果
(一)数据预处理
对获得的原始数据集,采用R语言分别进行缺失值处理、删除强相关变量、特征选择、数据标准化、数据分割等步骤,最终获得完整的可用于建模的数据集。
1. 变量筛选及特征选择:首先采用预测均值匹配(Predictive mean matching,PMM)方法进行缺失值补齐。对所有纳入变量进行相关性分析,并删除相关度大于0.9的同类变量,在本研究中,AST与ALT存在强相关性,故将AST排除出纳入分析变量。随后采用递归特征消除(Recursive Feature Elimination RFE)算法进行特征选择,结果表明:NSCLC vs SCLC模型在8个变量时可获得最佳准确率(图1 A),变量分别为ProGRP、NSE、cyfra211、SCC、LDH、CEA、WBC、LYM;LUAD vs LUSC模型在25个变量时可获得最佳准确率(图1 B),变量分别为SCC、CEA、Gender、cyfra211、CRE、ALP、Fbg、HB、ALT、Age、E、TP、ALB、HCT、GLU、WBC、PLT、NSE、LDH、UA、CK、URE、ProGRP、TBIL、LYM。
注:A:NSCLC与SCLC模型;B:LUAD与LUSC模型
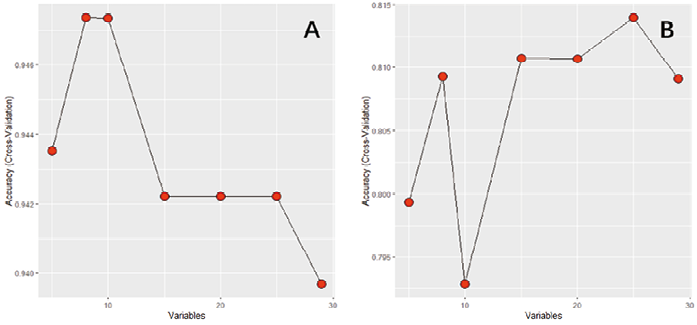
图1. 模型变量特征选择折线图
2. 数据分割:采用重复随机抽样的方法将数据集按照7:3的比例分为训练组和验证组。NSCLC与SCLC共780例,其中546例作为训练组,234例作为验证组。LUAD与LUSC共613例,其中429例作为训练组,184例作为验证组。各训练组和验证组组间变量无显著性差异(P>0.05)。
(二)模型建立及验证
1. NSCLC与SCLC模型:采用Caret函数包对最终的数据集进行建模和验证,结果显示,GLM、RF、NN、SVM、GBM5种模型的准确率分别为91.42%、94.85%、93.13%、91.42%和94.42%;敏感度分别为65.31%、83.67%、87.76%、69.39%和83.67%;特异度分别为98.37%、97.83%、94.57%、97.28%和97.28%。其中RF模型的准确率最高,NN模型的敏感度最好,GLM模型的特异度最高。
2. LUAD与LUSC模型:结果显示GLM、RF、NN、SVM、GBM5种模型的准确率分别为83.61%、80.87%、70.49%、77.60%和82.51%;敏感度分别为94.53%,92.19%、92.97%、93.75%和92.19%;特异度分别为58.18%、54.55%、18.18%、40.00%和60.00%。其中GLM的准确率和敏感度更高。但所有模型在诊断LUAC与LUSC时的特异性均不理想,较好的是GBM模型(表1)。
表1. 模型验证结果表
模型 | NSCLC与SCLC模型 | LUAD与LUSC模型 | ||||
准确率(%) | 敏感度(%) | 特异度(%) | 准确率(%) | 敏感度(%) | 特异度(%) | |
GLM | 91.42 | 65.31 | 98.37 | 83.61 | 94.53 | 58.18 |
RF | 94.85 | 83.67 | 97.83 | 80.87 | 92.19 | 54.55 |
NN | 93.13 | 87.76 | 94.57 | 70.49 | 92.97 | 18.18 |
SVM | 91.42 | 69.39 | 97.28 | 77.60 | 93.75 | 40.00 |
GBM | 94.42 | 83.67 | 97.28 | 82.51 | 92.19 | 60.00 |
(三)模型诊断实验评价
根据测试结果,以病理组织活检结果作为金标准,采用ROC曲线对模型性能进行评价,并计算曲线下面积(AUC)和95%可信区间,同时采用Kappa检验评价模型诊断与病理组织活检结果之间的一致性。
1. NSCLC与SCLC模型:5种模型ROC曲线下面积(AUC)分别为0.9359、0.9582、0.9576、0.9346和0.9562,其中RF模型的诊断性能最好。Kappa一致性检验的Kappa值分别为0.7113、0.8402、0.7993、0.7207和0.8282。5个模型一致性均较好(Kappa指数>0.4),RF模型为最佳。
2. LUAD与LUSC模型:5种模型ROC曲线下面积(AUC)分别0.8608、0.8614、0.7059、0.8193和0.8649,其中GBM模型性能最好。Kappa值分别为0.5748、0.5067、0.1371、0.3878和0.5565,除NN和SVM模型外,其他模型一致性均较好,GLM模型为最佳。
表2. 模型评价结果表
模型 | NSCLC与SCLC | LUAD与LUSC | ||
AUC | Kappa值 | AUC | Kappa值 | |
GLM | 0.9359 | 0.7113 | 0.8608 | 0.5748 |
RF | 0.9582 | 0.8402 | 0.8614 | 0.5067 |
NN | 0.9576 | 0.7993 | 0.7059 | 0.1371 |
SVM | 0.9346 | 0.7207 | 0.8193 | 0.3878 |
GBM | 0.9562 | 0.8282 | 0.8649 | 0.5565 |
注:A: NSCLC vs SCLC模型;B: LUAD vs LUSC模型
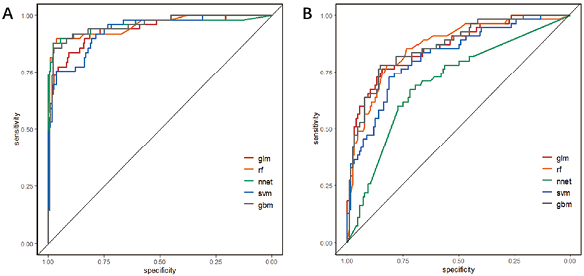
图2. 模型评价ROC曲线
三、分析与讨论
本研究采用机器学习算法结合临床常规的生化、免疫标志物来诊断鉴别肺癌病理类型,结果表明各类诊断模型的准确度、敏感度和特异度较高,与病理穿刺活检一致性较高。为了得到更有效的因变量分类模型,我们使用多种学习算法来建立模型,并对模型的最终诊断性能进行评估比较。多种算法的应用,使模型的容错能力得到了提高,而在自变量或因变量数目不同、数据类型不同时,不同的模型展现出性能的差异,这提示我们在选择建模方法时,可采用不同算法,最终择优。目前,ML技术主要用于肿瘤的分类鉴别及预后分析,如利用良性肺结节和肺癌患者的数据进行分类鉴别诊断,有助于良恶性结节的快速判断。采用患者术后转移、复发等预后数据可以建立预后评估模型等。
基于机器学习算法的建模技术在恶性肿瘤和其他疾病的诊断和预后评估中已被广泛应用,如Naresh Khuriwal团队采用神经网络模型(ANN)和Logistic回归模型进行乳腺癌的诊断,其准确率达到98.5%[7]。Ankita Tyagi[8]采用支持向量机、K-近邻、决策树算法建立模型诊断甲状腺疾病,其准确率达到98.62%、99.63%和75.76%。Priyanka Sonar等[9]采用机器学习算法建立了一个糖尿病风险预测模型,其准确性分别为77%、85%和77.3%。在本研究中,我们分别采用了GLM、RF、NN、SVM、GBM5类算法对肺癌病理组织类型进行分类。在NSCLC与SCLC的分类模型,各类算法模型准确率均超过90%,取得了很好的分类效果。而LUAD与LUSC模型的分类准确率均在70%~80%。两类诊断模型的效果差异主要来自于变量的选择,ProGRP是SCLC的特异标志物,主要用于SCLC的诊断、预后评估及疗效监测,也是SCLC单个指标中诊断特异性最高的。NSE是神经元和神经内分泌细胞所特有的一种酸性蛋白酶,也是SCLC最敏感的肿瘤标志物。CYFRA21-1则是NSCLC最有价值的血清肿瘤标志物,对患者的早期诊断、疗效观察、预后监测有重要意义。上述特异性标志物的使用使模型的输入层数据具有重要的权重效应,对后续的结果选择也有重要的价值。通常机器学习算法均存在过拟合现象,也就是建立的模型过度依赖对训练数据的拟合,而在新数据的推广使用中会出现准确率降低的情况。在本研究中,LUAC与LUSC肺癌诊断模型诊断效能不理想,除了与自变量的特异性有关外,也可能与纳入的自变量过多,导致的过度拟合有关。而其中GBM模型表现较好,这可能与梯度提升决策树模型中数量或迭代次数有关。
除了疾病诊断分类的应用外,机器学习技术也是精确医学领域的一个重要工具,对个体化治疗选择最佳治疗策略也有重要价值。此外,人工智能模型能够通过同时处理众多因素来发现数据中的相互联系和因果关系,这可能有助于更好地理解恶性肿瘤发生发展过程中的复杂机制[5]。总而言之,机器学习算法是传统医学诊断技术与信息化、智能化技术相结合的产物,随着大数据和深度学习算法领域的发展和进步,未来的智能化诊断取代传统的单纯依靠设备指标的诊断模式必将是大势所趋,也是检验医学未来研究和发展的方向。![]()
参考文献
Chen W, Zheng R, Baade PD, et al. Cancer statistics in China, 2015[J]. CA Cancer J Clin, 2016, 66(2):115-132.
Hirsch FR, Scagliotti GV, Mulshine JL, et al. Lung cancer:current therapies and new targeted treatments[J]. Lancet, 2017, 389 (10066): 299-311.
田文娟, 刘姗姗, 李步荣. 基于倾向性评分匹配评估肿瘤标志物对不同病理类型肺癌的诊断价值[J]. 国际检验医学杂志, 2020, 41(11): 1321-1325.
郎景和. 大数据及人工智能时代的医学[J]. 中国妇幼健康研究, 2019, 30(1): 1-3.
Kawakami E, Tabata J, Yanaihara N, et al. Application of artificial intelligence for preoperative diagnostic and prognostic prediction in epithelial ovarian cancer based on blood biomarkers [J]. Clin Cancer Res, 2019, 25(10): 3006-3015.
Cruz JA, Wishart DS. Applications of machine learning in cancer prediction and prognosis[J]. Cancer Inform, 2006, 2: 59-77.
Khuriwal N, Mishra N. Breast cancer diagnosis using adaptive voting ensemble machine learning algorithm[J]. IEEE, 2018, 卷 (期): 页?
Tyagi A, Mehra R, Saxena A. Interactive thyroid disease prediction system using machine learning technique. 5th IEEE international conference on parallel, distributed and grid computing (PDGC-2018).India, Solan: 2018.
Sonar PK. Malini J. Diabetes prediction using different machine learning approaches. proceedings of the third international conference on computing methodologies and communication (I.C.C.M.C. 2019) [J]. IEEE, 2019.


