


人工智能预测模型的建立与临床及实验室数据在原发性硬化性胆管炎和胆管癌风险评估的价值
【摘要】目的 原发性硬化性胆管炎(PSC)患者存在罹患胆管癌(CCA)的风险,建立PSC中CCA的预测模型具有重要意义。方法 在梅奥诊所(1993-2020年)就诊的1,459例PSC患者大型队列中,我们使用单变量和多变量Cox模型量化了临床/实验室变量对CCA发展的影响,并使用统计和人工智能(AI)方法预测了CCA。我们探索了血浆胆汁酸(BA)水平对CCA的预测能力(300例患者的子集,BA队列)。结果 单变量分析确定了8个显著风险因素(误报率:20%),其中最重要的是长期炎症性肠病(IBD)。多变量分析显示,IBD病期、PSC病期和总胆红素仍具有统计学意义(P<0.05)。在疾病的不同时间点,临床/实验室变量预测CCA的交叉验证C指数为0.68-0.71,显著优于常用的PSC风险评分。较低的鹅脱氧胆酸、较高的石胆酸和猪脱氧胆酸共轭分数、较高的胆酸/鹅脱氧胆酸比值可以预测CCA。BAs预测CCA的交叉验证C指数为0.66(标准差[std]:0.11,BA队列),与临床/实验室变量(C指数=0.64,std:0.11,BA队列)相似,将BAs与临床/实验室变量相结合可获得0.67的最佳平均C指数(std:0.13,BA队列)。结论 在一个大型PSC队列中,我们确定了CCA发展的临床和实验室危险因素,并证明了第一个基于AI的预测模型,其性能显著优于常用的PSC风险评分,这些模型的临床应用需要更多的预测数据模式。
【关键词】原发性硬化性胆管炎;胆管癌;危险因素;人工智能;胆汁酸
原发性硬化性胆管炎(PSC)是一种免疫介导的胆汁淤积性肝病,以胆管炎症和纤维化为特征,通常发展为终末期肝病,需要进行肝移植(LT)。近75%-80%的PSC患者合并有炎症性肠病(IBD),是胆管癌(CCA)的高发人群。据报道,PSC患者一生中罹患CCA的风险为7%-13%。尽管早期发现时CCA可以得到一定程度的治疗,但由于缺乏临床上有用的预测工具,CCA仍然是PSC患者死亡的重要原因。如果能预测PSC患者的CCA发展情况,就能制定出更好的监测计划,在可治愈的阶段发现CCA,从而改善预后。既往研究发现PSC患者发生CCA的危险因素包括高龄、男性、IBD病期延长。然而,其中许多研究样本量小,导致对危险因素效应量(effect sizes)的估计高度不确定。胆汁酸(BAs)被认为是与PSC的发展和发病机制有关的重要化学物质,可以使用廉价且无创的临床检测方法进行测量。个性化风险预测模型,例如,PSC风险评估工具(PREsTo),目前被用作评估PSC生存率和肝功能失代偿事件的临床决策工具。然而,通常需要大量样本和大量事件才能对模型进行可靠的训练,这阻碍了用于预测PSC中CCA的此类模型的开发。在这项研究中,我们利用最大的单中心表型良好的PSC队列之一,以更好地了解临床/实验室和血浆BA特征,并确定PSC中CCA发展的危险因素。采用严格的统计分析方法和人工智能(AI)方法,旨在通过建立个性化的CCA风险预测模型来缩小PSC的个体化治疗差距。希望我们的方法未来能够适用于针对PSC患者的多组学研究,并通过基于组学的个体风险信息监测项目为PSC提供更好的临床管理工具。
一、研究对象与方法
1. 患者人群:通过人工审核病历确定了在梅奥诊所的三个主要研究中心(明尼苏达州、佛罗里达州和亚利桑那州)和更广泛的梅奥诊所医疗系统接受治疗的PSC患者,并亲自或通过邮寄的方式邀请他们参与研究。所有可用的病历(电子版和纸质版)均由两名经验丰富的肝病专家全面审核。入选患者必须符合以下美国肝病研究协会指南既定的PSC诊断标准:(1)慢性胆汁淤积的生化证据(≥6个月);(2)胆管造影显示胆管多灶性狭窄和节段性扩张和/或符合PSC的组织学特征;(3)排除硬化性胆管炎的继发性原因。人工从患者病历中提取每位患者的人口统计学数据,还与PSC和IBD相关的临床数据、实验室数据、胆管造影数据、组织学数据和终点数据。
为了进行本研究,其中一名肝病专家重新审核了发生CCA的PSC患者的病历,并提取了以下有关CCA的数据:(1)诊断CCA的日期;(2)细胞学(阴性;异常;非典型;可疑或腺癌阳性);(3)荧光原位杂交(FISH)多体性;(4)最接近诊断CCA日期的血清糖类抗原19-9(CA19-9);(5)CCA类型(恶性狭窄;肿块);(6)组织病理学(良性;反应性;低度发育不良;高度发育不良或腺癌);(7)CCA的治疗类型(如有)(肝部分切除;肝移植;胆管全切除或全身化疗);(8)肝移植后肝组织中CCA残留的证据。CCA的诊断依据:(a)具有CCA特征的影像学/胆管造影,细胞学或组织病理学阳性;(b)FISH多体性且细胞学检查可疑的恶性狭窄;(c)FISH多体性且血清CA19-9升高的恶性狭窄;(d)FISH多体性的恶性狭窄;(e)血清CA19-9持续升高的恶性狭窄。记录胆囊癌(GBC)、肝细胞癌(HCC)、肝移植和非PSC原因导致的死亡,并将其视为竞争事件,根据已发表的标准诊断CBC和HCC。
2. 数据收集和预处理:从PSC患者的电子病历(EMR)中提取临床变量和实验室参数,用于基线队列分析。其中一部分患者的血浆BA数据来自之前的一项研究,该队列(在本研究中被定义为BA队列)被用于评估BAs改善CCA预测的潜力。临床变量包括性别、出生日期、PSC诊断日期、IBD诊断日期(如适用)、事件发生日期(CCA、GBC、HCC、LT诊断和死亡)、最后一次临床就诊日期以及通过终末期肝病模型(MELD)评分、MayoPSC风险评分和PREsTo评分评估PSC诊断时的疾病严重程度。PSC、IBD、CCA、GBC和HCC的诊断日期提前到记录日期前30天,以方便进行诊断检测。提取梅奥EMR中PSC诊断后、任何结果(即CCA、GBC、HCC、LT和死亡)发生前的首次可用实验室检测结果,并将其作为预测的基线测量值。实验室检测包括白蛋白、碱性磷酸酶(ALK)、丙氨酸转氨酶(ALT)、天冬氨酸转氨酶(AST)、总胆红素(总胆红素和直接胆红素)、CA19-9、全血细胞计数(血红蛋白、白细胞和血小板计数)、免疫球蛋白G(总IgG和IgG4)、国际标准化比值(INR)、钠和肌酐。缺失的参数首先使用过去一年内或基线后接下来七天内对相同实验室参数的最接近测量值来估算。部分患者的血浆初级和次级BAs数据包括CA、CDCA、DCA、LCA、UDCA、HDCA;牛磺酸共轭形式:TCA、TCDCA、TDCA、TLCA、TUDCA、THDCA;甘氨酸共轭形式:GCA、GCDCA、GDCA、GLCA、GUDCA和GHDCA。将所有评估的BA浓度相加,计算总BA浓度。BA“家族”的总浓度是通过非共轭和共轭形式相加来计算(如,总CA=CA+GCA+TCA)。共轭分数的计算方法是共轭形式的和除以总计(如,ConFrac CA=[GCA+TCA]/[CA+GCA+TCA])。G:T共轭比的计算方法是甘氨酸共轭除以牛磺酸共轭(例如,GTratio CA=GCA/TCA)。
3. CCA的发生率:我们分析了PSC患者GBC, HCC, LT的CCA发生率,将非PSC原因死亡作为竞争事件,未发生CCA或任何竞争性事件的患者在最后一次已知临床就诊时记为删失。使用mstate软件包生成累积发生率函数(CIF)用于依据竞争事件的CCA发生概率。
4. 风险因素的识别:采用Cox比例风险模型(CoxPH)来识别CCA发展的风险因素。在GBC、HCC、LT、死亡或最后一次临床就诊时记为删失,以先发生者为准。未被诊断为IBD的患者被认为IBD病期为0年。为了使CoxPH模型估算出的危险比(HRs)更易于解释,我们将年龄分为9个10年间隔的区间,并将年作为PSC病期和IBD病期的基线单位。将MELD评分、MayoPSC风险评分、PREsTo评分、血红蛋白和钠的实际值除以其四分位距(IQR)进行标准化。连续实验室参数和BAs的零值数据替换为最小非零值的一半。除血红蛋白和钠之外的实验室参数和 BAs都进行了对数转换(以10为底),因为它们高度右偏。首先为每个基线临床变量和实验室参数构建了单变量CoxPH模型,并使用95%置信区间(CI)报告p值和HRs。采用Benjamini-Hochberg程序将误报率(FDR)控制在20%以下。利用超过FDR临界值的基线因素构建了一个多变量CoxPH模型来估计基线因素的综合效应,并评估每个因素存在其他特征时的影响。在多变量模型中没有考虑综合评分(MayoPSC风险评分、PREsTo评分和MELD评分),因为它们是根据实验室参数计算的,会模糊HR解读。此外,排除了直接胆红素,因为我们发现直接胆红素与总胆红素高度相关(Pearson相关性=0.98)。BA队列的分析中使用了类似的方法。
5. 预测模型:(1)上述具有正则化项的多变量CoxPH模型;(2)随机生存森林(RSF);(3)梯度提升生存分析(GBSA)。CoxPH假设两组的HR随时间变化是恒定的,并且目标人群具有共同的基线风险函数,使用非参数Breslow的方法来估计基线风险,添加了L2和L1正则化项以减少过拟合的机会,并鼓励选择较少的特征。将这两个项的正则化参数设置为0.005。RSF和GBSA都是基于树的集成AI方法,可自动处理特征和结果之间的非线性关系。RSF是CoxPH用于生存分析的最受欢迎的基于学习的AI替代方案之一,而GBSA已广泛成功的应用于预测竞赛和医疗应用。RSF利用自助法构建多个生存树并对其结果取平均值以获得稳健的预测,选择对数秩(log-rank)统计量作为构建生存树的分割规则,根据弱大数定律使用100棵树来稳定性能。GBSA迭代学习一组决策树,决策树观察到生存结果的最大化偏对数似然。将树的数量设置为软件的默认值,100。对于RSF和GBSA,将每棵树的最大深度设置为3,以便在进行预测时允许特征之间的非线性三向交互,要求每个叶节点至少有30名患者才能进行可靠的估计。我们使用scikit-survival包在Python中实现了这三种方法。
采用C指数(C-index)评估预测性能,C指数值的范围0-1。高的C指数表明该模型正确预测了较短时间内患者发生CCA的较高风险。通过20倍蒙特卡洛交叉验证计算出了测试集C指数的平均值和标准差,其中训练-测试比例为80%-20%。具体来说,将数据集随机分为训练集(80%)和测试集(20%),并重复这一过程20次。计算结果是取所有20次拆分的测试集C指数的平均值和标准差,所有模型都采用相同的训练-测试拆分集,以确保公平的比较。通过测量每个模型的C指数在特征值被随机置换(跨测试集患者)时的下降情况来计算置换特征的重要性(PFI)。对于每个交叉验证折叠,重复排列3次,并评估测试集C指数的平均下降幅度。为了评估该模型在病程不同时间点的表现,还使用在PSC诊断后2年和5年收集的临床变量和实验室参数评估了模型,与时间相关的临床变量(如年龄和病期)根据评估时间点的状况进行了更新。
对于BA队列,利用血浆BAs和/或临床变量和实验室参数构建了第二套模型,非空值的复合BA变量也包括在内。采用了与上述相同的方法,除了由于BA 队列中的患者数量和CCA发生率较低,我们采用了更平衡的70%-30%训练-测试拆分,并在训练集上进行递归特征消除(RFE),以选择与CCA相关的3个最重要的BAs。在CoxPH中,由于明确进行了特征选择,我们放弃了L1正则化项,只使用了参数为0.01的L2正则化项,其他超参数的选择与基线队列模型保持一致。然后用选定的BA对模型进行训练,并在测试集上计算C指数。为了比较BAs、临床变量和实验室参数的预测能力,重复上述步骤,将BAs替换为临床/实验室变量。此外,我们结合所选的3个BAs和从相应的交叉验证折叠中选出3个临床/实验室变量来训练模型,通过三种排列再次测量特征重要性。
二、研究结果
1. 基线队列:基线队列共纳入1,459例PSC患者,特征见表1。基线中位年龄为44.2岁(IQR:32.7-55.2),64.2%的患者为男性。从PSC诊断到基线(即PSC诊断后首次可用的实验室检查)的中位时间为0.56年(IQR:0.16-3.47)。1,035例患者(70.9%)在基线时被诊断为IBD,中位IBD病期为8.45年(IQR:2.3-19.51),在基线队列中,记录了125例CCA(8.6%)、15例GBC(1.0%)和32例HCC(2.2%),四名患者同时患有CCA和GBC,两名患者同时患有CCA和HCC。从PSC确诊到最后一次就诊的中位时间为10.5年(IQR:5.2-17.8)。CCA累积发病率随时间呈线性增长,代表恒定发病率。PSC确诊后2、5、10和20年的CCA累积发生率分别为2.2%、5.3%、8.4%和15.9%。
2. CCA的诊断:在118例出现任何其他结果之前发展为CCA的PSC患者中,有78.8%(93/118)的患者在治疗前和/或治疗后经组织病理学和/或细胞学检查确诊为CCA。CCA治疗前52例细胞学诊断为腺癌,20例组织病理学诊断为腺癌,8例肝外植体组织病理学诊断为腺癌,6例肝部分切除标本组织病理学诊断为腺癌,6例肝脏/转移性肿块细针穿刺组织病理学诊断为腺癌,1例胆管整体切除。在25例未经组织学诊断的患者中,8例患者通过腹部横断面成像可见肿块,明确显示为CCA;6例为细胞学可疑且FISH多体的恶性狭窄;6例为细胞学阴性但FISH多体的恶性狭窄;5例为恶性狭窄且血清CA19-9升高。
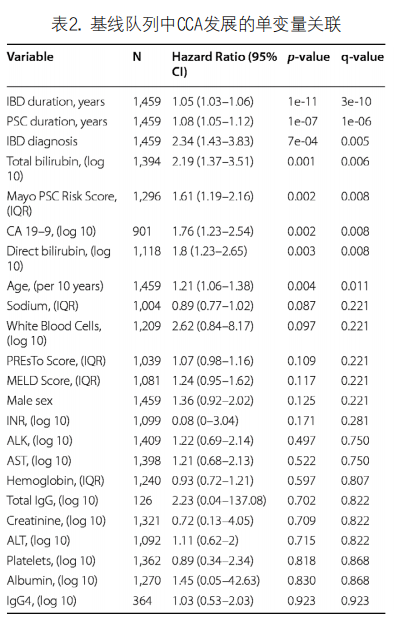
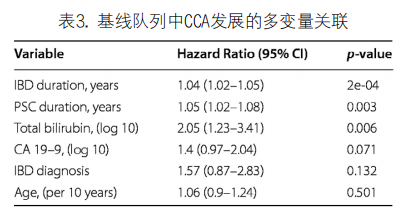
3. 风险因素识别:单变量CoxPH模型中的基线临床变量和实验室参数的HRs总结见表2。已发现,IBD病期长、PSC病期长、IBD诊断、高总胆红素、高MayoPSC风险评分、高CA19-9、高直接胆红素和年龄较大是CCA发展的独立预测因素,按显著性降序排列(FDR<20%)。低钠、高白细胞计数、高PREsTo评分、高MELD评分、男性的q值均为0.221,略高于20%FDR临界值。在单变量模型中使用通过20%FDR临界值的基线特征建立的多变量CoxPH模型见表3。IBD病期长、PSC病期长和较高的总胆红素在统计学上对CCA有显著的预测作用(P<0.05)。
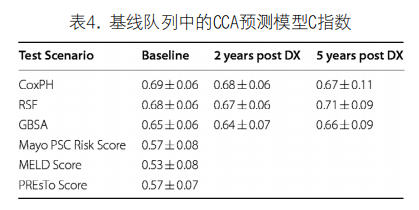
4. 预测模型:使用临床变量和实验室参数预测基线队列无CCA生存率的不同模型测试C指数值见表4。基线时,CoxPH的平均C指数最高(0.69,std:0.06),其次是RSF(C指数=0.68,std:0.06)。与常用的PSC评分(MayoPSC风险评分、MELD评分和PREsTo评分)相比,三个预测模型在预测CCA发展方面的表现都明显更好(任何一个预测模型与任何一个风险评分相比,P<0.005)。我们在PSC诊断后2年和5年两个时间点评估了模型的性能,与基线相比,两个时间点的每个模型C指数值均保持不变。
基线临床变量和实验室参数的置换特征重要性(PFI)如图1所示。IBD病期对3种模型具有最大的特征重要性,用随机排列值替换后,C指数平均下降0.11(CoxPH)、0.08(RSF)和0.12(GBSA)。在其余特征中,CA19-9水平、PSC病期、总胆红素和钠在不同模型中的特征重要性总和最大。
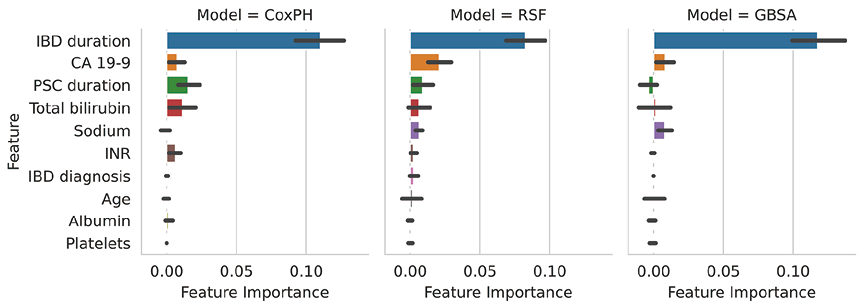
注:每个矩形的高度显示了该特征的平均重要性(跨交叉验证折叠);误差条表示95%置信区间;根据特征在模型间的重要性和交叉验证次数的总和由高到低排序。
图1. 基线临床变量和实验室参数的置换特征重要性
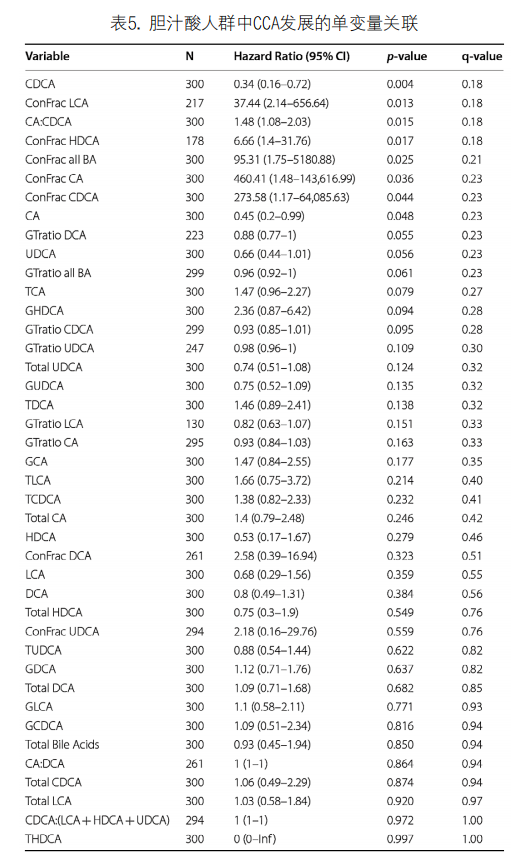
5. BAs对预测CCA的影响:在1,459例PSC患者中,300例有BA数据,构成了BA队列。300例患者从PSC诊断到最后一次就诊的中位时间为9.6年(IQR:5.6-17.1),在随访期间,21例(7.0%)患者被诊断为CCA。BAs预测CCA能力的单变量分析见表5。在单独 BAs中,控制FDR后,只有CDCA与CCA有统计学关联,其水平的增加似乎对CCA有保护作用。研究还发现,LCA和HDCA的共轭分数以及CA:CDCA的比值也具有预测作用,其值的增加与较高的CCA风险相关。值得注意的是,总BA,CA和CDCA的共轭分数增加也表面上与CCA风险增加相关(P<0.05),尽管当控制FDR时,它们没有统计学意义。
我们评估了与BA队列的临床变量和实验室参数相比,BAs的预测能力,最常见的特征如图2所示。当仅将BAs纳入建模时,RSF的平均C指数最好,为0.66(std:0.11),在递归特征消除过程中,CDCA是最常被选择的特征,其次是CDCA共轭分数和CA共轭分数(图2a),虽然GBSA模型表现不佳(平均C指数为0.61,std:0.11),但特征重要性与RSF相似。当仅将临床变量和实验室参数纳入建模时,CoxPH表现最佳,平均C指数为0.64(std:0.11)(图2b)。与临床变量和实验室参数相比,使用BA变量对GBSA的性能增益显著(P=0.036),对RSF的性能增益略微显著(P=0.054)。然而,CoxPH模型中使用BA变量的性能损失不显著(P=0.572)。将选定的临床变量、实验室参数和BAs结合起来时,RSF和GBSA模型的性能比仅使用临床/实验室变量时有所提高(P<0.01)(图2c),综合使用所有变量时的性能与单独使用BAs时相当。
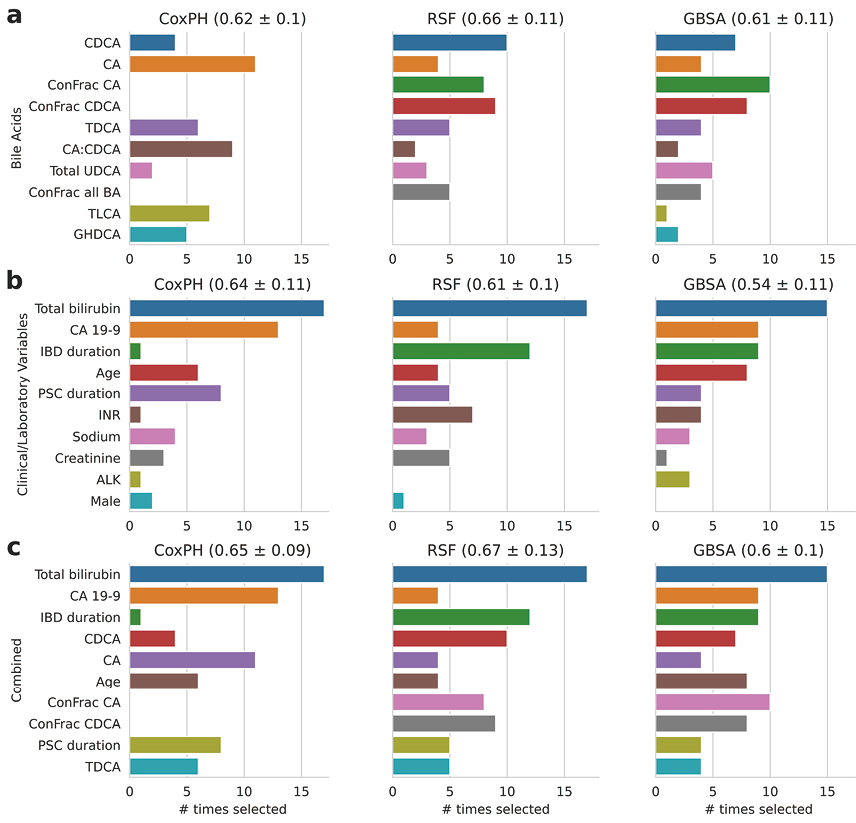
图2. BA队列中最常选择的特征,其预测模型C指数以平均值±标准差显示,该标准差通过20倍蒙特卡洛交叉验证估计. 每个矩形的高度显示了一个特征在20次折叠中被选中的次数,根据特征在模型中选择的时间和交叉验证次数的总和,降序排列
三、分析与讨论
在这项研究中,我们发现较长的IBD和PSC病史以及较高的胆红素和CA19-9是预测PSC患者发生CCA的最重要因素。发现,临床变量和实验室参数对 CCA的预测效果明显优于常用的风险评分,这些结果在PSC病程中具有普遍性,在PSC确诊后2年和5年的表现相似。通过对部分患者的研究,发现除了临床变量和常规实验室参数外,BAs能略微改善对CCA的预测。CCA是PSC患者发病和死亡的最常见原因之一,目前尚缺乏具有高敏感性和特异性的准确生物标志物来预测PSC患者的CCA,肝脏生化或胆汁淤积的恶化以及腹痛和黄疸等症状的出现应引起对CCA的怀疑。然而,许多并发CCA的PSC患者并无症状,美国肝病研究协会最近更新了指南,建议通过横断面成像(联合或不联合CA19-9)对PSC患者进行CCA常规筛查,然而,用于筛查的成像方式和CA19-9的最佳临界值仍存在争议。因此,确定CCA的标志物和建立预测模型是PSC中未满足临床需求的重要领域。我们的分析表明,较长的IBD病期是基线时CCA的最重要风险因素,这与之前的报告一致。进一步研究IBD和CCA癌变之间的联系超出了本文的范围,但我们假设,长期的肠壁损伤导致肠屏障的中断,进而导致胆道系统暴露于促进肿瘤的物质,如细菌产物/毒素和有毒的BAs。基线时的PSC病期也是导致CCA的一个重要风险因素,这一点不足为奇,同时也凸显了这些患者患CCA的持续风险。
CA19-9是一种众所周知的血清肿瘤标记物,已被发现在胃肠道上皮性肿瘤(如胰腺癌和胆道癌)过表达。许多医疗中心将CA19-9用作PSC患者的CCA筛查标志物。据报道,CA19-9检测CCA的灵敏度和特异性各不相同,分别在50%-90%和54%-98%之间,虽然CA19-9是预测PSC患CCA的有效标志物,但存在一些局限性,包括在一些非CCA疾病(如吸烟)、良性胆道梗阻和上行性胆管炎患者中CA19-9升高。我们的单变量分析显示,CA19-9水平每增加10倍,罹患CCA的风险就会增加1.8倍,这为CA19-9预测PSC患者CCA的建议价值提供了依据。以往的研究显示,胆红素在预测PSC患者CCA方面的作用存在相互矛盾的结果,Burak等人报告了一个单变量CoxPH模型,结果发现血清胆红素不是PSC患者发生CCA的重要风险因素,然而,我们发现胆红素在单变量和多变量模型中均具有统计学意义,这与之前的多篇报道一致。胆红素与CCA发展之间的关系尚不清楚,但我们推测血清胆红素浓度会随着胆道狭窄的形成而升高,这可能导致未来CCA的发展。
虽然已有研究确定了PSC患者发生CCA的风险因素,但目前还缺乏能估计无CCA生存率的个体化预测模型。据我们所知,我们构建了首个用于预测PSC患者无CCA生存率的个体化预测模型。虽然需要更高的C指数值,但相信我们的工作是对现有文献的重要补充,因为我们的队列是拥有充分记录的最大单中心PSC人群之一。模型对PSC中CCA的预测明显优于常用的风险评分(MayoPSC风险评分、MELD评分和PREsTo评分),虽然MayoPSC风险评分和MELD评分以死亡为终点,而PREsTo则以肝功能失代偿(腹水、静脉曲张出血或脑病)为终点,但它们并没有考虑CCA的风险因素,如IBD病期或CA19-9,而在我们的个性化模型中,这些因素被证明是最重要的预测因素。本研究的数据证实,PSC患者的CCA是临床、生化、遗传和环境因素的复杂相互作用,仅使用常规获得的临床和实验室变量可能无法识别。部分假定的复杂交互作用可能由BAs来解释。因此,我们检测了血浆BA数据作为预测PSC中CCA发展的附加数据模式,结果表明,在BA队列中,BAs预测CCA的C指数为0.66。在相同的BA队列中,临床变量和实验室参数预测CCA的C指数为0.64,略低于基于BAs的预测,联合所选BAs、临床变量和实验室参数的预测性能最佳,C指数为0.67。值得注意的是,可用于训练的CCA病例数量相对较少(平均15例))阻碍了模型准确学习预测因素与CCA之间关系的能力。此外,我们仅选择了三个特征(在组合场景中为六个特征)以减少过度拟合。对BA队列的初步结果表明,BAs提高了CCA预测的效果,超越了临床变量和常规实验室参数,因此在更大的患者群体中研究BAs的可预测性非常有价值,更大的队列将使模型能够准确地学习关系,并从更广泛的特征集中保留更丰富的信息。
AI涉及计算机程序,这些程序可以执行与人类智能相关的功能,如学习。AI技术在预测疾病结果方面大有可为,并越来越多地应用于消化内科。为了解AI在预测PSC中CCA发展的效用,我们实施了两种AI算法RSF和GBSA,并将它们与经典的CoxPH模型进行了比较。CoxPH依赖于比例风险假设,而RSF和GBSA不存在这种假设,因此有能力揭示预测因素和结果之间的复杂关系。然而,当样本量较小时,RSF和GBSA容易过度拟合训练数据中的随机波动,导致测试集上的泛化效果不理想。在我们的分析中确实存在这种情况,尤其是 GBSA,在利用基线队列中的临床变量和实验室参数预测CCA时,CoxPH和 RSF的表现最佳。尽管我们通过超参数选择有意识地对RSF和GBSA模型进行了正则化,但仍然观察到它们的训练和测试性能之间存在很大差距,这表明存在过拟合。在BA队列中,仅使用临床变量和实验室参数,CoxPH再次具有最佳性能,表明比例风险假设可能非常适合捕捉临床变量、实验室参数和CCA之间的关系。然而,在这种假设下,潜在的非线性效应和预测因素的相互作用将被忽略,这可能是RSF在使用BAs作为预测因素时预测CCA的性能优于CoxPH的原因。RSF和GBSA在BA队列中也观察到过拟合,这表明需要更大的BA队列来减轻过拟合,这可能有助于实现AI算法的强大能力。
我们的研究有一些局限性。虽然其在预测PSC患者CCA方面提供了有价值的初步结果,并显示个体化预测模型显著优于常用的风险评分,但需要性能更好的模型才能直接用于临床。我们相信,目前的工作为今后开发更准确的CCA风险判断工具奠定了基础,而这正是临床实践所急需的。横截面数据的使用限制了我们对不同风险因素随时间变化的重要性进行评论的能力,这可以通过纵向数据来解决。本研究中的患者主要在学术性、高流量的三级医疗中心就诊,因此更有可能是固有的复杂病例,此外,与其他医疗中心相比,我们的PSC人群中CCA病例的频率更高,因为我们的机构是这些疾病的转诊中心。因此,本研究结果不一定适用于整个PSC人群,需要注意的是,我们结果的临床适用性需要在一个独立的PSC队列中进行交叉验证。我们使用的CCA诊断标准可能与其他医疗中心不同。由于CCA的临床表现隐匿,且缺乏准确敏感的标志物,因此在PSC患者中,CCA的诊断极具挑战性,需要临床高度怀疑,结合实验室、影像学和内镜综合评估,细胞学阳性虽然对CCA的特异性为100%,但灵敏度很低,仅为20%。因此,鉴于传统细胞学的局限性,最近开发了其他细胞学技术。例如,梅奥医学中心的研究人员开发并使用胆道FISH作为诊断CCA的另一种工具,检测CCA的灵敏度为65%,而不影响特异性。
在一项研究中,在77%的CCA病例中观察到胆道FISH多体性。我们的医学中心使用恶性狭窄和胆道FISH多体性相结合作为CCA的诊断标准。在我们的研究中,少数病例的CCA诊断是基于恶性狭窄和血清CA19-9的持续升高,而非细菌性胆管炎,因此,少数患者可能并不是CCA,只有1/4纳入患者的血清IgG4水平可用。但我们注意到,在目前的研究队列中,没有PSC患者具有提示IgG4相关疾病(IgG4-RD)临床或影像学特征,因此只有极少数患者可能患有IgG4相关硬化性胆管炎(IgG4-SC),并被误诊为PSC。我们的分析中合并了不同表型的CCA(例如按位置分类,即肝内和肝外CCA),在未来的研究中应考虑基于不同CCA表型的模型。虽然我们提出了PSC患者中CCA的血浆BA特征,并显示了改善CCA预测的前景,但需要更大的队列来验证我们的结果。此外,磁共振成像/磁共振胰胆管造影(MRI/MRCP)等成像技术可提供胆管和周围组织的详细图像,其应用已被证明可准确预测与PSC相关的并发症,如肝功能失代偿时间和肝脏相关性死亡。然而,目前还缺乏使用MRI/MRCP预测PSC患者CCA的数据。调整我们的方法以纳入影像学数据可能会在未来产生更好的预测模型。最后,PSC和PSC中CCA的复杂性要求对遗传和环境因素进行全面检查和整合,以阐明病理生理学并改进预测模型,本研究为建立基于多组学的PSC CCA个体化预测模型迈出了第一步。
四、结论
在一个大规模的PSC队列中,我们确定了CCA发展的临床和实验室危险因素,并研究了一种统计学学习方法和两种AI方法,这些方法预测CCA发展的预测效果显著优于常见的风险评分。我们探索了BAs作为新型生物标志物的使用,有望改善CCA预测。这些模型的临床应用需要更大规模的研究和新的生物标志物研究,以改善这些患者的治疗。![]()
本文编译自:《BMC Gastroenterol》. 2023;23:129


